Лекция
Создание БД с помощью SQL .
Манипулирование данными в SQL
В состав языка SQL входят язык описания данных, позволяющий управлять таблицами, и язык манипулирования данными, служащий для управления данными (слайд 2 ).
17.1. Построение баз данных с помощью SQL
17.1.1. Команда создания таблицы – CREATE TABLE
Создание таблицы выполняется при помощи команды CREATE TABLE. Обобщенный синтаксис команды следующий (слайд 3 ).
Т.е. после задания имени таблицы через запятую в круглых скобках должны быть перечислены все предложения, определяющие отдельные элементы таблицы – столбцы или ограничения целостности:
имя_таблицы – идентификатор создаваемой таблицы, который в общем случае строится из имени базы данных, имени владельца таблицы и имени самой таблицы.При этом комбинация имени таблицы и ее владельца должна быть уникальной в пределах базы данных. Если таблица создается не в текущей базе данных, в ее идентификатор необходимо включить имя базы данных.
определение_столбца – задание имени, типа данных и параметров отдельного столбца таблицы. Названия столбцов должны соответствовать правилам для идентификаторов и быть уникальными в пределах таблицы.
определение_ограничения_таблицы – задание некоторого ограничения целостности на уровне таблицы.
Описание столбцов
Как видно из синтаксиса команды CREATE TABLE, для каждого столбца указывается предложение <определение_столбца>, с помощью которого и задаются свойства столбца. Предложение имеет следующий синтаксис ( слайд 3 ) :
Рассмотрим назначение и использование параметров.
Имя_столбца – идентификатор, задающий имя столбца таблицы.
тип_данных – задает тип данных столбца. Если при определении столбца явно не указано ограничение на хранения значений NULL, то будут использованы свойства типа данных, т.е. если выбранный тип данных позволяет хранить значения NULL, то и в столбце можно будет хранить значения NULL. Если же при определении столбца в команде CREATE ТАBLE явно будет разрешено или запрещено хранение значений NULL, то свойства типа данных будут перекрыты установленным на уровне столбца ограничением. Например, если тип данных позволяет хранить значения NULL, а на уровне столбца будет установлен запрет, то попытка вставки значения NULL в столбец закончится ошибкой.
ограничение_столбца – с помощью этого предложения указываются ограничения, которые будут определены для столбца. Синтаксис предложения следующий (слайд 4 ):
Рассмотрим назначение параметров.
CONSTRAINT – необязательное ключевое слово, после которого указывается название ограничения на значения столбца (имя_ограничения). Имена ограничений должны быть уникальны в пределах базы данных.
DEFAULT – задает значение по умолчанию для столбца. Это значение будет использовано при вставке строки, если для столбца явно не указано никакое значение.
NULL|NOT NULL – ключевые слова, разрешающие (NULL) или запрещающие (NOT NULL) хранение в столбце значений NULL. Если для столбца не задано значение по умолчанию, то при вставке строки с неизвестным значением для столбца будет предприниматься попытка вставки в столбец значения NULL. Если при этом для столбца указано ограничение NOT NULL, то попытка вставки строки будет отклонена, и пользователь получит соответствующее сообщение об ошибке.
PRIMARY KEY – определение первичного ключа на уровне одного столбца (т.е. первичный ключ будет состоять только из значений одного столбца). Если необходимо сформировать первичный ключ на базе двух и более столбцов, то такое ограничение целостности должно быть задано на уровне таблицы. При этом следует помнить, что для каждой таблицы может быть создан только один первичный ключ.
UNIQUE – указание на создание для столбца ограничения целостности UNIQUE, что позволит гарантировать уникальность каждого отдельного значения в столбце в пределах этого столбца. В таблице может быть создано несколько ограничений целостности UNIQUE.
FOREIGN KEY ... REFERENCES – указание на то, что столбец будет служить внешним ключом для таблицы, имя которой задается с помощью параметра <имя_главной_таблицы>.
(имя_столбца [,...,n]) – столбец или список перечисленных через запятую столбцов главной таблицы, входящих в ограничение FOREIGN KEY. При этом столбцы, входящие во внешний ключ, могут ссылаться только на столбцы первичного ключа или столбцы с ограничением UNIQUE таблицы.
ON DELETE {CASCADE | NO ACTION} – эти ключевые слова определяют действия, предпринимаемые при удалении строки из главной таблицы. Если указано ключевое слово CASCADE, то при удалении строки из главной (родительской) таблицы строка в зависимой таблице также будет удалена. При указании ключевого слова NO ACTION в подобном случае будет выдана ошибка. Значением по умолчанию является вариант NO ACTION.
ON UPDATE {CASCADE | NO ACTION} – эти ключевые слова определяют действия, предпринимаемые при модификации строки главной таблицы. Если указано ключевое слово CASCADE, то при модификации строки из главной (родительской) таблицы строка в зависимой таблице также будет модифицирована. При использовании ключевого слова NO ACTION в подобном случае будет выдана ошибка. Значением по умолчанию является вариант NO ACTION.
CHECK – ограничение целостности, инициирующее контроль вводимых в столбец (или столбцы) значений.
логическое_выражение – логическое выражение, используемое для ограничения CHECK.
Ограничения на уровне таблицы
Синтаксис команды CREATE TABLE предусматривает использование предложения <ограничение_таблицы>, с помощью которого определяются ограничения целостности на уровне таблицы. Синтаксис предложения следующий (слайд 5 ) .
Назначение параметров совпадает с назначением аналогичных параметров предложения <ограничение_столбца > . Тем не менее, в предложении <ограничение_таблицы> имеются некоторые новые параметры:
имя_колонки – столбец (или список столбцов), на которые необходимо наложить какие-либо ограничения целостности.
– метод упорядочивания данных в индексе. Индекс создается при указании ключевых слов PRIMARY KEY, UNIQUE. При указании значения ASC данные в индексе будут упорядочены по возрастанию, при указании значения DESC – по убыванию. По умолчанию используется значение ASC.
Примеры создания таблиц
В качестве примера рассмотрим инструкции создания таблиц базы данных «Сессия»:
Таблица «Студенты» состоит из следующих столбцов:
ID_Студент – тип данных INTEGER, уникальный ключ;
Номер_группы - тип данных CHAR, длина 6;
слайд 6 ).
Адрес и Телефон, наложены ограничения NOT NULL
Для создания таблицы «Дисциплины» была использована команда (слайд 7 ).
Таблица содержит 2 столбца (ID _Дисциплина , Наименование ).
На столбцы ID _Дисциплина , Наименование наложены ограничения NOT NULL , запрещающие ввод строки при неопределенном значении столбца.
Столбец ID _Дисциплина объявлен первичным ключом, а на значения, вводимые в столбец Наименование, наложено условие уникальности.
Таблица «Учебный_план» включает в себя следующие столбцы:
ID_Дисциплина – тип данных INTEGER;
Семестр - тип данных INTEGER;
Количество_часов - тип данных INTEGER;
Создание таблицы выполнялось с помощью следующей команды (слайд 8 ).
Для значений столбца Семестр сформулировано логическое выражение, разрешающее вводить только значения от 1 до 10.
Таблица «Сводная_ведомость» состоит из следующих столбцов:
ID_Студент – тип данных INTEGER, столбец уникального ключа;
ID_План – тип данных INTEGER, столбец уникального ключа;
Оценка - тип данных INTEGER;
Дата_сдачи - тип данных DATETIME;
ID_Преподаватель - тип данных INTEGER.
Создание таблицы выполнялось с помощью следующей команды (слайд 9 ).
На все столбцы таблицы наложены ограничения NOT NULL , запрещающие ввод строки при неопределенном значении столбца.
Для значений столбца Оценка сформулировано логическое выражение, разрешающее вводить только значения от 0 до 5: 0 – незачет, 1 – зачет, 2 – неудовлетворительно, 3 – удовлетворительно, 4 – хорошо, 5 – отлично.
И, наконец, перечислим столбцы «Кадровый_состав»:
ID_Преподаватель – тип данных INTEGER, уникальный ключ;
Фамилия – тип данных CHAR, длина 30;
Имя - тип данных CHAR, длина 15;
Отчество - тип данных CHAR, длина 20;
Должность - тип данных CHAR, длина 20;
Кафедра - тип данных CHAR, длина 3;
Адрес - тип данных CHAR, длина 30;
Телефон - тип данных CHAR, длина 8.
Создание таблицы выполнялось с помощью следующей команды (слайд 10 ).
На все столбцы таблицы, кроме столбцов Адрес и Телефон, наложены ограничения NOT NULL , запрещающие ввод строки при неопределенном значении столбца.
Для таблиц «Учебный_план» и «Сводная_ведомость» должны быть построены внешние ключи, связывающие таблицы базы данных «Сессия»:
FK_Дисциплина – внешний ключ, связывающий таблицы «Учебный_план» и «Дисциплины» по столбцу ID_Дисциплина;
FK_Кадровый_состав – внешний ключ, связывающий таблицы «Учебный_план» и «Кадровый_состав» по столбцу ID_Преподаватель;
FK_Студент – внешний ключ, связывающий таблицы «Сводная_ведомость» и «Студенты» по столбцу ID_Студент;
FK_План – внешний ключ, связывающий таблицы «Сводная_ведомость» и «Учебный_план» по столбцу ID _План.
Добавление внешних ключей в таблицы рассмотрим далее при обсуждении возможностей команды ALTER TABLE .
17.1.2. Изменение структуры таблицы – команда ALTER TABLE
Как бы тщательно ни планировалась структура таблицы, иногда возникает необходимость внести в нее некоторые изменения. Предположим, что в уже сформированную таблицу «Преподаватели» необходимо добавить номер домашнего телефона и домашний адрес. Эту операцию можно выполнять различными путями. Например, можно удалить таблицу со старой структурой и создать вместо нее новую таблицу с нужной структурой. Недостатком этого метода является то, что необходимо будет куда-то скопировать имеющиеся в таблице данные и переписать их в новую таблицу после ее создания.
Специальная команда ALTER TABLE предназначена для модификации структуры таблицы. С ее помощью можно изменять свойства существующих столбцов, удалять или добавлять в таблицу столбцы, а также управлять ограничениями целостности как на уровне столбца, так и на уровне таблицы, т.е. выполнять следующие функции:
Добавить в таблицу определение нового столбца;
Удалить столбец из таблицы;
Изменить значение по умолчанию для какого-либо столбца;
Добавить или удалить первичный ключ таблицы;
Добавить или удалить внешний ключ таблицы;
Добавить или удалить условие уникальности;
Добавить или удалить условие на значение.
Обобщенный синтаксис команды ALTER TABLE представлен на слайде (слайд 11 ).
Команда ALTER TABLE берет на себя все действия по копированию данных во временную таблицу, удалению старой таблицы, созданию вместо нее новой таблицы с нужной структурой и последующим переписыванием в нее данных.
Назначение многих параметров и ключевых слов команды ALTER TABLE аналогично назначению соответствующих параметров и ключевых слов команды CREATE TABLE (например, синтаксис конструкции <определение_столбца> совпадает с синтаксисом аналогичной конструкции команды CREATE TABLE ).
Основные режимы использования команды ALTER TABLE следующие:
Добавление столбца;
Удаление столбца;
Модификация столбца;
Изменение, добавление и удаление ограничений (первичных и внешних ключей, значений по умолчанию).
Добавление столбца
Для добавления нового столбца следует использовать ключевое слово ADD , после которого должно стоять определение столбца.
Добавим, например, в таблицу «Студенты» столбец «Год_поступления» (слайд 12 ). После выполнения этой команды в структуру таблицы «Студент» будет добавлен еще один столбец со значением по умолчанию, равным текущему году (значение по умолчанию вычисляется с помощью двух встроенных функций - YEAR () и GETDATE ()).
Модификация столбца
Для модификации существующего столбца таблицы служит ключевое слово ALTER COLUMN . Изменение свойств столбца невозможно, если:
столбец участвует в ограничениях PRIMARY KEY или FOREIGN KEY;
на столбец наложены ограничения целостности CHECK или UNIQUE (исключение составляют столбцы, имеющие тип данных переменной длины, т.е. типы данных, начинающиеся на var);
если со столбцом связано значение по умолчанию (в этом случае допускается изменение длины, общего количества цифр или количества цифр после десятичной точки при неизменном типе данных).
Определяя для столбца новый тип данных, следует помнить о том, что старый тип данных должен конвертироваться в новый.
Пример модификации столбца «Номер_группы» таблицы «Студенты» (тип данных INTEGER заменяется на CHAR ) (слайд 12 ).
Удаление столбца
Для удаления столбца из таблицы используется предложение DROP COLUMN <имя_столбца>. При удалении столбцов следует учитывать, что нельзя удалять столбцы сограничениями целостности CHECK , FOREIGN KEY , UNIQUE или PRIMARY KEY , а также столбцы, для которых определены значения по умолчанию (в виде ограничения целостности на уровне столбца или на уровне таблицы).
Рассмотрим, например, команду удаления из таблицы «Студент» столбца «Год_поступления» (слайд 12 ).
Эта команда выполнена не будет, т.т. при добавлении столбца было определено значение по умолчанию.
Добавление ограничений на уровне таблицы
Для добавления ограничений на уровне таблицы используется предложение ADD CONSTRAINT <имя_ограничения>.
В качестве примера рассмотрим команды добавления внешних ключей в таблицы базы данных «Сессия» (слайд 13 ):
· добавление внешних ключей в таблицу «Учебный_план» (создание связи с именем FK _Дисциплина и связи с именем FK _ Кадровый_состав);
· добавление внешних ключей в таблицу «Сводная_ведомость» (создание связи с именем FK _Студент и связи с именем FK _План).
С помощью конструкции ADD CONSTRAINT создается поименованное ограничение. Необходимо отметить, что удаление любого ограничения на уровне таблицы происходит только по его имени, поэтому ограничение должно быть поименовано (чтобы его можно было удалить).
Удаление ограничений
Для удаления из таблицы ограничения целостности используется предложение DROP CONSTRAINT <имя_ограничения>.
Удаление ограничения целостности возможно только в том случае, когда оно поименовано (т.е. предложение <определение_ограничения> содержит именование ограничения CONSTRAINT ).
Команда удаления построенного внешнего ключа FK _Дисциплина из таблицы «Учебный_план» выглядит следующим образом (слайд 14 ).
На слайде (слайд 14 ) показано удаление построенного ранее ограничения на значение по умолчанию DEF _Номер_группы.
17.1.3. Удаление таблиц – команда DROP TABLE
Удаление таблицы выполняется при помощи команды DROP TABLE (слайд 14 ).
Единственный аргумент команды задает имя таблицы, которую необходимо удалить.
Операция удаления таблицы в некоторых случаях требует определенного внимания. Невозможно удалить таблицу, если на нее с помощью ограничения целостности FOREIGN KEY ссылается другая таблица: попытка удаления таблицы «Дисциплины» вызовет сообщение об ошибке, т.к. на таблицу дисциплины ссылается таблица «Учебный_план».
17.2. Управление данными
Целью любой системы управления базами данных в конечном счете является ввод, изменение, удаление и выборка данных. Рассмотрим методы управления данными с помощью языка SQL.
17.2.1. Извлечение данных – команда SELECT
Основным инструментом выборки данных в языке SQLявляется команда SELECT . С помощью этой команды можно получить доступ к данным, представленным как совокупность таблиц практически любой сложности.
Чаще всего используется упрощенный вариант команды SELECT , имеющий следующий синтаксис (слайд 15 ).
Инструкция SELECT разбивается на отдельные разделы, каждый из которых имеет свое назначение. Из приведенного синтаксического описания видно, что обязательными являются только разделы SELECT и FROM , а остальные разделы могут быть опущены. Полный список разделов приведен на слайде (слайд 15 ).
Раздел SELECT
Основное назначение раздела SELECT (одного из двух обязательных разделов, которые должны указываться в любом запросе) - задание набора столбцов, возвращаемых послевыполнения запроса, т.е. внешнего вида результата. В простейшем случае возвращается столбец одной из таблиц, участвующих в запросе. В более сложных ситуациях набор значений в столбце формируется как результат вычисления выражения. Такие столбцы называются вычисляемыми и по умолчанию им не присваивается никакого имени.
При необходимости пользователь может указать для столбца, возвращаемого после выполнения запроса, произвольное имя. Такое имя называется псевдонимом (alias ). В обычной ситуации назначение псевдонима не обязательно, но в некоторых случаях требуется явное его указание. Наиболее часто это требуется при работе с разделом INTO , в котором каждый из возвращаемых столбцов должен иметь имя, и это имя должно быть уникально.
Помимо сказанного, с помощью раздела SELECT можно ограничить количество строк, которое будет включено в результат выборки. Синтаксис раздела SELECT следующий (слайд 16 ).
Рассмотрим назначение параметров.
Ключевые слова ALL | DISTINCT . При указании ключевого слова ALL в результат запроса выводятся все строки, удовлетворяющие сформулированным условиям, тем самым разрешается включение в результатодинаковых строк (одинаковость строк определяется на уровне результата отбора, а не на уровне исходных данных). Параметр ALL используется по умолчанию.
Если в запросе SELECT указывается ключевое слово DISTINCT , то в результат выборки не будет включаться более одной повторяющейся строки. Таким образом, каждая возвращенная строка будет уникальной. Уникальность строки при этом определяется на уровне строк результата выборки, а не на уровне исходных данных. Если в результат выборки включаются два столбца, уникальность будет определяться по значениям обоих этих столбцов. В отдельности значения в первом и втором столбцах могут повторяться, но комбинация значений в обоих столбцах должна быть уникальна. Аналогичные правила действуют и в отношении большего количества столбцов.
Рассмотрим результат использования ключевых слов ALL и DISTINCT на примере выборки столбцов Семестр и Отчетность из таблицы «Учебный_план» базы данных «Сессия» (слайд 17 ). Сначала выполним запрос с указанием ключевого слова ALL . Фрагмент результата представлен на слайде. Теперь заменим ключевое слово ALL на DISTINCT . В этом случае результат запроса, представленный на слайде - это строки, содержащие одинаковые значения в столбцах, включенные только один раз. Этот результат должен свидетельствовать только о наличии различных форм отчетности в семестрах.
Ключевое слово TOP n . Использование ключевого слова ТОР n, где n – числовое значение, позволяет отобрать в результат не все строки, а только n первых. При этом выбираются первые строки результата выборки, а не исходных данных. Поэтому набор строк в результате выборки при указании ключевого слова ТОР может меняться в зависимости от порядка сортировки. Если в запросе используется раздел WHERE , то ключевое слово ТОР работает с набором строк, возвращенных после применения логического условия, определенного в разделе WHERE .
Продемонстрируем использование ключевого слова ТОР (слайд 18 )
В этом примере из таблицы Студенты базы данных «Сессия» было выбрано 5 первых строк.
Можно также выбирать не фиксированное количество строк, а определенный процент от всех строк, удовлетворяющих условию. Для этого необходимо добавить ключевое слово PERCENT .
Всего в таблице было 115 строк, следовательно, 10% будет составлять 11,5 строк. В результате будут выданы 12 строк.
Если указанное количество процентов строк представляет собой нецелое число, то сервер всегда выполняется округление в большую сторону.
Приведем также пример, демонстрирующий влияние порядка сортировки на возвращаемый набор строк (слайд 19 ).
При указании вместе с предложением ORDER BY ключевого слова WITH TIES в результат будут включены еще и строки, совпадающие по значению колонки сортировки с последними выведенными строками запроса SELECT TOP n [ PERCENT ].
Использование ключевого слова WITH TIES в предыдущем примере позволит обеспечить выдачу в ответ на запрос информации обо всех студентах первой по порядку группы (слайд 20 ).
Предложение <Список_выбора>. Синтаксис предложения <Список_выбора>следующий (слайд 21 ).
Символ «*» означает включение в результат всех столбцов, имеющихся в списке таблиц раздела FROM .
Если в результат не нужно включать все столбцы всех таблиц, то можно явно указать имя объекта, из которого необходимо выбрать все столбцы (<Имя_таблицы>.* или <Псевдоним_таблицы>.*).
Отдельный столбец таблицы в результат выборки включается явным указанием имени столбца (параметр <Имя_столбца>). Столбец должен принадлежать одной из таблиц, указанных в разделе FROM. Если столбец с указанным именем имеется более чем в одном источнике данных, перечисленных в разделе FROM, то необходимо явно указать имя источника данных, к которому принадлежит столбец в формате <Имя_таблицы>.<Имя_столбца>.В противном случае будет выдано сообщение об ошибке.
Например, попробуем выбрать данные из столбца ID_Дисциплина, который имеется в таблицах «Дисциплина» и «Учебный_план»:
В ответ будет выдано сообщение об ошибке, указывающее на некорректное использование имени‘ID_Дисциплина".
Т. е., в этом случае необходимо явно указать имя источника данных, которому принадлежит столбец, например:
Столбцам, возвращаемым как результат выполнения запроса, могут быть присвоены псевдонимы. Псевдонимы позволяют изменить имя исходного столбца или поименовать столбец, содержимое которого получено как результат вычисления выражения. Имя псевдонима указывается с помощью параметра <Псевдоним_столбца>. Ключевое слова AS необязательно при задании псевдонима. В общем случае сервер не требует уникальности имен столбцов результата выборки, поэтому разные столбцы могут иметь одинаковые имена или псевдонимы.
Столбцы в результате выборки могут быть не только копией столбца одной из исходных таблиц, но и формироваться на основе вычисления выражения. Такой столбец в списке выбора задается с помощью конструкции <Выражение> [ <Псевдоним_столбца>]. Выражение при этом может содержать константы, имена столбцов, функции, а также их комбинации. Дополнительно столбцу, формируемому на основе вычисления выражения, можно присвоить псевдоним, указав его с помощью параметра <Псевдоним_столбца>. По умолчанию вычисляемый столбец не имеет имени.
Другой способ формирования вычисляемого столбца состоит в использовании конструкции со знаком равенства: <Псевдоним_столбца> = <Выражение>. Единственным отличием этого способа от предыдущего является необходимость обязательного задания псевдонима. В простейшем случае выражение является именем столбца, константой, переменной или функцией. Если в качестве выражения выступает имя столбца, то получаем еще один способ задания псевдонима для столбца.
Рассмотрим следующий пример. Пусть для таблицы «Студенты» необходимо построить запрос, представляющий фамилию, имя и отчество в одной колонке. Используя операцию конкатенации (сложения) символьных строк и значение ФИО в качестве псевдонима столбца, построим запрос (слайд 22 ).
Раздел FROM
С помощью раздела FROM определяются источники данных, с которыми будет работать запрос.
Синтаксис раздела FROM следующий (слайд 23 )
На первый взгляд конструкция раздела выглядит простой. Однако при ближайшем рассмотрении он оказывается довольно сложным. В основном работа с разделом FROM это перечисление через запятую источников данных, с которыми должен работать запрос. Собственно источник данных указывается с помощью предложения <Источник_данных>, синтаксис которого представлен на слайде.
С помощью параметра <имя_таблицы> указывается имя обычной таблицы. Параметр <псевдоним_таблицы> используется для присвоения таблице псевдонима, под которым на нее нужно будет ссылаться в запросе. Часто псевдонимы таблиц применяют, чтобы ссылку на нужную таблицу сделать более удобной и короткой. Например, если в запросе часто упоминается имя таблицы «Учебный_план», то можно воспользоваться псевдонимом, например, tpl . Указание ключевого слова AS не является при этом обязательным.
Раздел WHERE
Раздел WHERE предназначен для наложения вертикальных фильтров на данные, обрабатываемые запросом. Другими словами, с помощью раздела WHERE можно сузить набор строк, включаемых в результат выборки. Для этого указывается логическое условие, от которого зависит, будет ли строка включена в выборку по запросу или нет. Строка включается в результат выборки, только если логическое выражение возвращает значение TRUE .
В общем случае логическое выражение содержит имена столбцов таблиц, с которыми работает запрос. Для каждой строки, возвращенной запросом, вычисляется логическое выражение путем подстановки вместо имен столбцов конкретных значений из соответствующей строки. Если при вычислении выражения возвращается значение TRUE , то есть выражение истинно, то строка будет включена в конечный результат. В противном случае строка в результат не включается. При необходимости можно указать более одного логического выражения, объединив их с помощью логических операторов OR и AND .
Рассмотрим синтаксис раздела WHERE (слайд 24 ).
В конструкции <условие_отбора> можно определить любое логическое условие, при выполнении которого строка будет включена в результат.
Приведенный на слайде пример демонстрирует логику работы раздела WHERE . В результате будет возвращен список всех студентов, поступивших на факультет ранее 2000 года.
Помимо операций сравнения (=, >, <, >=, <=) и логических операторов OR , AND , NOT при формировании условия отбора могут быть использованы дополнительные логические операторы, расширяющие возможности по управлению данными. Рассмотрим некоторые из этих операторов.
Оператор BETWEEN . С помощью этого оператора можно определить, лежит ли значение указанной величины в заданном диапазоне. Синтаксис использования оператора следующий (слайд 25 ).
<Выражение> задает проверяемую величину, а аргументы <начало_диапазона> и <конец_диапазона> определяют возможные границы ее изменения. Использование оператора NOT совместно с оператором BETWEEN позволяет задать диапазон, вне которого может изменяться проверяемая величина.
При выполнении оператор BETWEEN преобразуется в конструкцию из двух операций сравнения.
Рассмотрим пример использования оператора BETWEEN (слайд 25 ). В результате выполнения инструкции получим список дисциплин учебного плана с количеством часов от 50 до 100.
Оператор IN . Оператор позволяет задать в условии отбора множество возможных значений для проверяемой величины. Синтаксис использования оператора следующий (слайд 26 ).
<Выражение> указывает проверяемую величину, а аргументы <выражение1>,…, <выражение N > задают перечислением через запятую набор значений, которые может принимать проверяемая величина. Ключевое слово NOT выполняет логическое отрицание.
Рассмотрим пример применения оператора IN (слайд 26 ). В результате выполнения инструкции получим строки учебного плана для дисциплин «Английский язык» и «Физическая культура».
Оператор LIKE . С помощью оператора LIKE можно выполнять сравнение выражения символьного типа с заданным шаблоном. Синтаксис оператора следующий (слайд 27 ).
<Образец> задает символьный шаблон для сравнения и заключается в кавычки. Шаблон может содержать символы-разделители. Допускается использование следующих символов-разделителей (слайд 27 ):
% - может быть заменен в символьном выражении любым количеством произвольных символов;
_ - может быть заменен в символьном выражении любым, но только одним символом;
[ ABC 0-9] - может быть заменен в символьном выражении только одним символом из указанного в квадратных скобках набора (дефис используется для указания диапазона);
[^ ABC 0-9] - может быть заменен в символьном выражении только одним символом, кроме тех, что указаны в квадратных скобках (дефис используется для указания диапазона).
Рассмотрим пример использования оператора (слайд 27 ). Применение образца для значения столбца Должность в данном случае позволило отобрать строки со значениями «Ст.преп.» и «Проф»
Раздел ORDER BY
Раздел ORDER BY предназначен для упорядочения набора данных, возвращаемого после выполнения запроса. Полный синтаксис раздела ORDER BY следующий (слайд 28 ).
Параметр <условие_сортировки> требует задания выражения, в соответствии с которым будет осуществляться сортировка строк. В простейшем случае это выражение представляет собой имя столбца одного из источников данных запроса.
Следует отметить, что в выражении, в соответствии с которым осуществляется сортировка строк, могут использоваться и столбцы, не указанные в разделе SELECT, то есть не входящие в результат выборки.
Раздел ORDER BY разрешает использование ключевых слов ASC и DESC, с помощью которых можно явно указать, каким образом следует упорядочить строки. При указании ключевого слова ASC данные будут отсортированы по возрастанию. Если необходимо отсортировать данные по убыванию, указывается ключевое слово DESC. По умолчанию используется сортировка по возрастанию.
Данные можно отсортировать по нескольким столбцам. Для этого необходимо ввести имена столбцов через запятую по порядку сортировки. Сначала данные сортируются по столбцу, имя которого было указано первым в разделе ORDER BY . Затем, если имеется множество строк с одинаковыми значениями в первом столбце, выполняется дополнительная сортировка этих строк по второму столбцу (внутри группы с одинаковым значением в первом столбце) и т.д.
Приведем пример сортировки по двум столбцам (слайд 28 ).
Раздел UNION
Раздел UNION служит для объединения результатов выборки, возвращаемых двумя и более запросами.
Рассмотрим синтаксис раздела UNION (слайд 29 ).
Чтобы к результатам запросов можно было применить операцию объединения, они должна соответствовать следующим требованиям:
запросы должны возвращать одинаковый набор столбцов (причем необходимо гарантировать одинаковый порядок следования столбцов в каждом из запросов);
типы данных соответствующих столбцов второго и последующих запросов должны поддерживать неявное преобразование или совпадать с типом данных столбцов первого запроса;
ни один из результатов не может быть отсортирован с помощью раздела ORDER BY (однако общий результат может быть отсортирован, как будет показано ниже)
Указание ключевого слова ALL предписывает включать в результат повторяющиеся строки. По умолчанию повторяющиеся строки в результат не включаются.
Продемонстрируем применение раздела UNION . Рассмотрим таблицы «Кадровый_Состав» и «Студенты» и попробуем построить, например, общий список и учащихся, и преподавателей, номер телефона которых начинается на 120. Упорядочим полученный список по алфавиту, добавив предложение ORDER BY (слайд 29 ).
При объединении таблиц столбцам итогового набора данных всегда присваиваются те же имена, что были указаны в первом из объединяемых запросов.
Для этого понадобится установленная система управления базами данных (СУБД) DB2. Мы будем использовать диалект языка SQL, который используется именно в этой СУБД.
Первая команда, которую мы будем применять для создании базы данных - это команда CREATE DATABASE. Её синтаксис следующий:
CREATE TABLE ИМЯ_ТАБЛИЦЫ (имя_первого_столбца тип данных, ..., имя_последнего_столбца тип данных, первичный ключ, ограничения (не обязательно))
Так как наша база данных моделирует сеть аптек, то в ней есть такие сущности, как "Аптека" (таблица Pharmacy в нашем примере создания базы данных), "Препарат" (таблица Preparation в нашем примере создания базы данных), "Доступность (препаратов в аптеке)" (таблица Availability в нашем примере создания базы данных), "Клиент" (таблица Client в нашем примере создания базы данных) и другие, которые здесь подробно и разберём.
Разработке модели "сущность-связь" можно посвятить не одну статью, но если нас прежде всего интересуют команды языка SQL для создания базы данных и таблиц в ней, то условимся считать, что связи между сущностями уже нам понятны. На рисунке ниже приведено представление модели нашей базы данных с атрибутами сущностей (таблиц) и связями между таблицами.
Для увеличения рисунка можно нажать на него левой кнопкой мыши.
Как уже говорилось, в разбираемом здесь примере создания базы данных использовался вариант языка SQL, который используется в системе управления базами данных (СУБД) DB2. Он является регистронезависимым, то есть не имеет значение, набраны ли команды и отдельные слова в них строчными или прописными буквами. Для иллюстрации этой особенности приведены команды без особой системы набранные строчными и прописными буквами.
Теперь приступим к созданию команд. Первая наша команда SQL создаёт базу данных PHARMNETWORK:
Код SQL
CREATE DATABASE PHARMNETWORK
Описание таблицы PHARMACY (Аптека):
Пишем команду, которая создаёт таблицу PHARMACY (Аптека), значения первичного ключа PH_ID генерируются автоматически от 1 с шагом 1, вносится проверка на то, чтобы значения атрибута Address в этой таблице были уникальными:
Код SQL
CREATE TABLE PHARMACY(PH_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), Address varchar(40) NOT NULL, PRIMARY KEY(PH_ID), CONSTRAINT PH_UNIQ UNIQUE(Address))
Описание таблицы GROUP (Группа препаратов):
Пишем команду, которая создаёт таблицу Group (Группа препаратов), значения первичного ключа GR_ID генерируются автоматически от 1 с шагом 1, проводится проверка уникальности наименования группы (для этого используется ключевое слово CONSTRAINT):
Код SQL
CREATE TABLE GROUP(GR_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), Name varchar(40) NOT NULL, PRIMARY KEY(GR_ID), CONSTRAINT GR_UNIQ UNIQUE(Name))
Описание таблицы PREPARATION (Препарат):
Команда, которая создаёт таблицу PREPARATION, значения первичного ключа PR_ID генерируются автоматически от 1 с шагом 1, определяется, что значения внешнего ключа GR_ID (Группа препаратов) не могут принимать значение NULL, определена проверка уникальности значений атрибута Name:
Код SQL
CREATE TABLE PREPARATION(PR_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), Name varchar(40) NOT NULL, GR_ID int NOT NULL, PRIMARY KEY(PR_ID), constraint PR_UNIQ UNIQUE(Name))
Далее нам требуется позаботиться об ограничениях целостности. Это очень удобно слелать с помощью команды alter table. Эта команда изучается на уроке SQL ALTER TABLE - изменение таблицы базы данных.
Теперь самое время создать таблицу AVAILABILITY (Доступность или Наличие препарата в аптеке). Её описание:
Пишем команду, которая создаёт таблицу AVAILABILITY. Определяются даты начала (не может быть NULL) и окончания (по умолчанию NULL).
Код SQL
CREATE TABLE AVAILABILITY(A_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), PH_ID INT NOT NULL, PR_ID INT NOT NULL, DateStart varchar(20) NOT NULL, DateEnd varchar(20) DEFAULT NULL, QUANTITY INT NOT NULL, MART varchar(3) DEFAULT NULL, PRIMARY KEY(A_ID), CONSTRAINT AVA_UNIQ UNIQUE(PH_ID, PR_ID))
Создаём таблицу DEFICIT (Дефицит препарата в аптеке, то есть, неудовлетворённый запрос). Её описание:
Пишем команду, которая создаёт таблицу DEFICIT:
Код SQL
CREATE TABLE DEFICIT(D_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), PH_ID INT NOT NULL, PR_ID INT NOT NULL, Solution varchar(40) NOT NULL, DateStart varchar(20) NOT NULL, DateEnd varchar(20) DEFAULT NULL)
Осталось немного. Мы уже дошли до команды, которая создаёт таблицу Employee (Сотрудник). Её описание:
Пишем команду, которая создаёт таблицу Employee (Сотрудник), с первичным ключом, генерируемым по тем же правилам, что и первичные ключи предыдущих таблиц, в которых они существуют. Внешним ключом PH_ID Сотрудник связан с PHARMACY (Аптекой).:
Код SQL
CREATE TABLE EMPLOYEE(E_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), F_Name varchar(40) NOT NULL, L_Name varchar(40) NOT NULL, POST varchar(40) NOT NULL, PH_ID INT NOT NULL, PRIMARY KEY(E_ID))
Очередь дошла до создании таблицы CLIENT (Клиент). Её описание:
Пишем команду, создающую таблицу CLIENT (Клиент), в отношении первичного ключа которого справедливо предыдущее описание. Особенность этой таблицы в том, что её атрибуты F_Name и L_Name имеют по умолчанию значение NULL. Это связано с тем, что клиенты могут быть как зарегистрированными, так и незарегистрированными. У последних значения имени и фамилии как раз и будут неопределёнными (то есть NULL):
Код SQL
CREATE TABLE CLIENT(C_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), FName varchar(40) DEFAULT NULL, LName varchar(40) DEFAULT NULL, DateReg varchar(20), PRIMARY KEY(C_ID))
Предпоследняя таблица в нашей базе данных - таблица BASKET (Корзина покупок). Её описание:
Пишем команду, создающую таблицу BASKET (Корзина покупок), так же с уникальным и инкрементируемым первичным ключом и связанную внешним ключами C_ID и E_ID с Клиентом и Сотрудником соответственно:
Код SQL
CREATE TABLE BASKET(BS_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), C_ID INT NOT NULL, E_ID INT NOT NULL, PRIMARY KEY(BS_ID))
И, наконец, последняя таблица в нашей базе данных - таблица BUYING (покупка). Её описание:
| Имя поля | Тип данных | Описание |
| B_ID | smallint | Идентификационный номер покупки |
| PH_ID | smallint | Идентификационный номер аптеки |
| PR_ID | smallint | Идентификационный номер препарата |
| BS_ID | varchar(40) | Идентификационный номер корзины покупок |
| Price | varchar(20) | Цена |
| Date | varchar(20) | Дата |
Пишем команду, создающую таблицу BUYING (покупка), так же с уникальным и инкрементируемым первичным ключом и связанную внешними ключами BS_ID, PH_ID, PR_ID с Корзиной покупок, Аптекой и Препаратом соответственно:
Код SQL
CREATE TABLE BUYING(B_ID smallint NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), BS_ID INT NOT NULL, PH_ID INT NOT NULL, PR_ID INT NOT NULL, DateB varchar(20) NOT NULL, Price Double NOT NULL, PRIMARY KEY(B_ID))
И совсем уже в завершение темы создания базы данных обещанное отступление о соблюдении ограничений целостности, когда решение - более сложное, чем написание команды. В нашем примере необходимо соблюдать следующее условие: при покупке единицы препарата значение количества этого препарата в таблице AVAILABILITY должно соответственно уменьшиться. Вообще говоря, для таких операций в языке SQL существуют особые средства, называемые триггерами. Но триггеры - вещь капризная: на практике они могут и не сработать или сработать не так, как предусмотрено. Поэтому разработчики по возможности ищут программные средства решения таких задач, пример которых упомянут в этом абзаце.
Инсталлируйте программное обеспечение SQL Server Management Studio. Это программное обеспечение можно бесплатно загрузить с сайта Microsoft. Оно позволяет вам подключаться и управлять вашим SQL сервером через графический интерфейс вместо того, чтобы использовать командную строку.
Запустите SQL Server Management Studio. При первом запуске программы вам будет предложено выбрать, к какому сервер подключаться. Если у вас уже есть сервер и вы работаете, имеете необходимые разрешения для подключения к нему, то можете ввести адрес сервера и идентификационную информацию. Если вы хотите создать локальную базу данных, установите имя базы данных Database Name как. и тип аутентификации как "Windows Authentication".
- Нажмите кнопку Подключить чтобы продолжить.
Определите место для папки Databases. После выполнения соединения с сервером (локальное или удаленное), откроется окно обозревателя объектов Object Explorer в левой стороне экрана. В верхней части дерева обозревателя объектов будет сервер, к которому вы подключены. Если дерево не расширено, нажмите на значок "+" рядом с ним. Определите место папки базы данных Databases.
Создайте новую базу данных. Щелкните правой кнопкой мыши по папке Databases и выберите пункт "New Database...". Появится окно, которое позволяет настроить базу данных перед ее созданием. Дайте имя базе данных, которое поможет вам идентифицировать ее. Большинство пользователей могут оставить значения остальных настроек по умолчанию.
- Вы заметите, что при вводе имени базы данных два дополнительных файла будут созданы автоматически: Data и Log. Файл данных (Data) вмещает все данные в вашей базе данных, в то время как файл журнала (Log) отслеживает изменения в базе данных.
- Нажмите кнопку OK, чтобы создать базу данных. Вы увидите вашу новую базу данных, которая появится в развернутой папке Databases. Она будет иметь значок цилиндра.
Создайте таблицу. База данных может только хранить данные, если вы создаете структуру для этих данных. Таблица содержит информацию, которую вы вводите в вашу базу данных, и вам нужно будет создать ее, прежде чем можете продолжить. Разверните новую базу данных в папке Databases, и щелкните правой кнопкой мыши на папке Tables и выберите пункт "New Table...".
- Windows откроется в остальной части экрана, позволяя вам управлять вашей новой таблицей.
Создайте Primary Key (первичный ключ). Настоятельно рекомендуется, чтобы вы создавали первичный ключ в качестве первого столбца в вашей таблице. Он действует как идентификационный номер, или номер записи, что позволит вам легко выводить эти записи позже. Для его создания введите "ID" в столбце Name field, тип int в поле Data Type и снимите флажок "Allow Nulls". Нажмите на значок Key iна панели инструментов, чтобы установить этот столбец в качестве Primary Key (первичного ключа).
- Вы же не хотите допустить нулевые значения, так как всегда хотите иметь запись по крайней мере "1". Если вы разрешите 0, ваша первая запись будет "0".
- В окне Column Properties прокрутите вниз, пока не найдете опцию Identity Specification. Разверните ее и установите "(ls Identity)" на "Yes". Эта опция автоматически увеличит значение столбца ID для каждой записи, автоматически нумеруя каждую новую запись.
Разберитесь, как устроены таблицы. Таблицы состоят из полей или столбцов. Каждый столбец представляет один из аспектов записи базы данных. Например, если вы создаете базу данных сотрудников, вы можете иметь столбец "FirstName", столбец "LastName", столбец "Address" и столбец "PhoneNumber".
Создайте остальные столбцы. Когда закончите заполнение полей для Primary Key, заметите, что новые поля появляются под ним. Это позволит вам войти в свой следующий столбец. Заполните поля, как считаете нужным, и убедитесь, что правильно выбрали тип данных для информации, которая будет введена в этом столбце:
- nchar(#) - это тип данных следует использовать для текста, как имена, адреса и т.д. Число в скобках – это максимальное количество символов, разрешенное для это го поля. Установление лимита гарантирует, что ваш размер базы данных остается управляемым. Номера телефонов должны быть сохранены в этом формате, так как вы не выполняете математические функции с ними.
- int - это целые числа, и обычно используются в поле идентификатора.
- decimal(x,y) - будут хранить числа в десятичной форме, а числа в скобках обозначают соответственно общее количество цифр и количество цифр после десятичной. Например, decimal(6,2) будет сохранять числа как 0000.00.
Сохраните вашу таблицу. Когда вы закончите создавать свои столбцы, то вам нужно сохранить таблицу перед вводом информации. Щелкните на значке Save на панели инструментов, а затем введите название таблицы. Рекомендуется присваивать имя таблице таким образом, чтобы оно помогло вам распознать содержимое, особенно для больших баз данных с несколькими таблицами.
Добавьте данные в вашу таблицу. После того, как вы сохранили таблицу, можете начать добавлять в нее данные. Откройте папку Tables в окне обозревателя объектов Object Explorer. Если вашей новой таблицы нет в списке, щелкните правой кнопкой мыши на папке Tables и выберите Refresh. Щелкните правой кнопкой мыши по таблице и выберите "Edit Top 200 Rows".
Последнее обновление: 09.07.2017
Создание базы данных
Для создания базы данных используется команда CREATE DATABASE .
Чтобы создать новую базу данных откроем SQL Server Management Studio. Нажмем на назначение сервера в окне Object Explorer и в появившемся меню выберем пункт New Query .
В центральное поле для ввода выражений sql введем следующий код:
CREATE DATABASE usersdb
Тем самым мы создаем базу данных, которая будет называться "usersdb":
Для выполнения команды нажмем на панели инструментов на кнопку Execute или на клавишу F5. И на сервере появится новая база данных.
После создания базы даных, мы можем установить ее в качестве текущей с помощью команды USE :
USE usersdb;
Прикрепление базы данных
Возможна ситуация, что у нас уже есть файл базы данных, который, к примеру, создан на другом компьютере. Файл базы данных представляет файл с расширением mdf, и этот файл в принципе мы можем переносить. Однако даже если мы скопируем его компьютер с установленным MS SQL Server, просто так скопированная база данных на сервере не появится. Для этого необходимо выполнить прикрепление базы данных к серверу. В этом случае применяется выражение:
CREATE DATABASE название_базы_данных ON PRIMARY(FILENAME="путь_к_файлу_mdf_на_локальном_компьютере") FOR ATTACH;
В качестве каталога для базы данных лучше использовать каталог, где хранятся остальные базы данных сервера. На Windows 10 по умолчанию это каталог C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA . Например, пусть в моем случае файл с данными называется userstoredb.mdf. И я хочу этот файл добавить на сервер как базу данных. Вначале его надо скопировать в выше указанный каталог. Затем для прикрепления базы к серверу надо использовать следующую команду:
CREATE DATABASE contactsdb ON PRIMARY(FILENAME="C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\DATA\userstoredb.mdf") FOR ATTACH;
После выполнения команды на сервере появится база данных contactsdb.
Удаление базы данных
Для удаления базы данных применяется команда DROP DATABASE , которая имеет следующий синтаксис:
DROP DATABASE database_name1 [, database_name2]...
После команды через запятую мы можем перечислить все удаляемые базы данных. Например, удаление базы данных contactsdb:
DROP DATABASE contactsdb
Стоит учитывать, что даже если удаляемая база данных была прикреплена, то все равно будут удалены все файлы базы данных.
1 голосПриветствую вас на моем блоге сайт. Сегодня поговорим про sql запросы для начинающих. У некоторых вебмастеров может возникнуть вопрос. Зачем изучать sql? Разве нельзя обойтись ?
Оказывается, что для создания профессионального интернет-проекта этого будет недостаточно. Sql используется чтобы работать с БД и создания приложений для Вордпресс. Рассмотрим, как использовать запросы подробнее.
Что это такое
Sql - язык структурированных запросов. Создан для определения типа данных, предоставления доступа к ним и обработке информации за короткие промежутки времени. Он описывает компоненты или какие-то результаты, которые вы хотите видеть на интернет-проекте.
Если говорить по-простому, то этот язык программирования позволяет добавлять, изменять, искать и отображать информацию в БД. Популярность mysql связана с тем, что он используется для создания динамических интернет-проектов, основа которых составляет база данных. Поэтому для разработки функционального блога вам необходимо выучить этот язык.

Что может делать
Язык sql позволяет:
- создавать таблицы;
- изменять получать и хранить разные данные;
- объединять информацию в блоки;
- защитить данные;
- создавать запросы в access.
Важно! Разобравшись с sql вы сможете писать приложения для Вордпресс любой сложности.
Какая структура
БД состоит из таблиц, которые можно представить в виде Эксель файла.
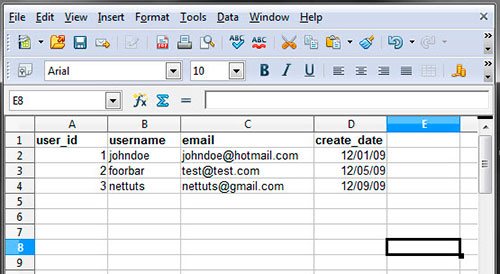
У нее имеется имя, колонки и ряд с какой-то информацией. Создавать подобные таблицы можно при помощи sql запросов.
Что нужно знать

Основные моменты при изучении Sql
Как уже отмечалось выше, запросы применяются для обработки и ввода новой информации в БД, состоящую из таблиц. Каждая ее строка - это отдельная запись. Итак, создадим БД. Для этого напишите команду:
Create database ‘bazaname’
В кавычках пишем имя БД на латинице. Старайтесь придумать для нее понятное имя. Не создавайте базу типа «111», «www» и тому подобное.
После создания БД устанавливаем :
SET NAMES ‘utf-8’
Это нужно чтобы контент на сайте правильно отображаться.
Теперь создаем таблицу:
CREATE TABLE ‘bazaname’ . ‘table’ (
id INT(8) NOT NULL AUTO_INCREMENT PRIMARY KEY,
log VARCHAR(10),
pass VARCHAR(10),
date DATE

Во второй строке мы прописали три атрибута. Посмотрим, что они означают:
- Атрибут NOT NULL означает, что ячейка не будет пустой (поле обязательное для заполнения);
- Значение AUTO_INCREMENT — автозаполнение;
- PRIMARY KEY — первичный ключ.
Как добавить информацию
Чтобы заполнить поля созданной таблицы значениями, используется оператор INSERT. Пишем такие строки кода:
INSERT INTO ‘table’
(login , pass , date) VALUES
(‘Vasa’, ‘87654321’, ‘2017-06-21 18:38:44’);
В скобках указываем название столбцов, а в следующей - значения.
Важно! Соблюдайте последовательность названий и значений столбцов.
Как обновить информацию
Для этого используется команда UPDATE. Посмотрим, как изменить пароль для конкретного пользователя. Пишем такие строки кода:
UPDATE ‘table’ SET pass = ‘12345678’ WHERE id = ‘1’
Теперь поменяйте пароль ‘12345678’. Изменения происходят в строке с «id»=1. Если не писать команду WHERE - поменяются все строки, а не конкретная.
Рекомендую вам приобрести книгу «SQL для чайников ». С ее помощью вы сможете шаг за шагом профессионально работать с БД. Вся информация построена по принципу от простого к сложному, и будет хорошо восприниматься.

Как удалить запись
Если вы написали что-то не так, исправьте это при помощи команды DELETE. Работает так же, как и UPDATE. Пишем такой код:
DELETE FROM ‘table’ WHERE id = ‘1’
Выборка информации
Для извлечения значений из БД используется команда SELECT. Пишем такой код:
SELECT * FROM ‘table’ WHERE id = ‘1’
В данном примере в таблице выбираем все имеющиеся поля. Это происходит если прописать в команде звездочку «*». Если нужно выбрать какое-то выборочное значение пишем так:
SELECT log , pass FROM table WHERE id = ‘1’
Необходимо отметить, что умения работать с базами данных будет недостаточно. Для создания профессионального интернет-проекта придется научиться добавлять на страницы данные из БД. Для этого ознакомьтесь с языком веб-программирования php. В этом вам поможет классный курс Михаила Русакова .

Удаление таблицы
Происходит при помощи запроса DROP. Для этого напишем такие строки:
DROP TABLE table;
Вывод записи из таблицы по определенному условию
Рассмотрим такой код:
SELECT id, countri, city FROM table WHERE people>150000000
Он отобразит записи стран где населения больше ста пятидесяти миллионов.
Объединение
Связать вместе несколько таблиц возможно используя Join. Как это работает посмотрите подробнее в этом видео:
PHP и MySQL
Еще раз хочу подчеркнуть, что запросы при создании интернет-проекта - это обычное дело. Чтобы их использовать в php-документах выполните такой алгоритм действий:
- Соединяемся с БД при помощи команды mysql_connect();
- Используя mysql_select_db() выбираем нужную БД;
- Обрабатываем запрос при помощи mysql_fetch_array();
- Закрываем соединение командой mysql_close().
Важно! Работать с БД не сложно. Главное - правильно написать запрос.
Начинающие вебмастера подумают. А что почитать по этой теме? Хотелось бы порекомендовать книгу Мартина Грабера «SQL для простых смертных ». Она написана так, что новичкам все будет понятно. Используйте ее в качестве настольной книги.

Но это теория. Как же обстоит дело на практике? В действительности интернет-проект нужно не только создать, но еще и вывести в ТОП Гугла и Яндекса. В этом вас поможет видеокурс «Создание и раскрутка сайта ».

Видео инструкция
Остались еще вопросы? Посмотрите подробнее онлайн видео.
Вывод
Итак, разобраться с написанием sql запросов не так трудно, как кажется, но сделать это нужно любому вебмастеру. В этом помогут видеокурсы, описанные выше. Подпишитесь на мою группу ВКонтакте чтобы первыми узнавать о появлении новой интересной информации.