В данной статье речь пойдет об алгоритме HEngine и реализации решения проблемы подсчета расстояния Хэмминга на больших объемах данных.
Введение
Расстояние Хэмминга - это количество различающихся позиций для строк с одинаковой длинной. Например, HD(100, 001) = 2.
Впервые проблема подсчета расстояния Хэмминга была поставлена Minsky и Papert в 1969 году , где задача сводилась к поиску всех строк из базы данных, которые находятся в пределах заданного расстояния Хэмминга к запрашиваемой.
Подобная задача является необычайно простой, но поиск ее эффективного решения до сих пор остается на повестке дня.
Расстояние Хэмминга уже довольно широко используется для различных задач, таких как поиск близких дубликатов, распознавание образов, классификация документов, исправление ошибок, обнаружения вирусов и т.д.
Например, Manku и сотоварищи предложили решение проблемы кластеризации дубликатов при индексации веб документов на основе подсчета расстояния Хэмминга .
Также Miller и друзья предложили концепцию поиска песен по заданному аудио фрагменту , .
Подобные решения были использованы и для задачи поиска изображений и распознавание сетчатки , и т.д.
Описание проблемы
Имеется база данных бинарных строк T , размером n , где длина каждой строки m . Запрашиваемая строка a и требуемое расстояние Хэмминга k .
Задача сводится к поиску всех строк, которые находятся в пределах расстояния k .
В оригинальной концепции алгоритма рассматривается два варианта задачи: статическая и динамическая.
В статическая задачи расстояние k предопределено заранее.
- В динамической, наоборот, требуемое расстояние заранее неизвестно.
В статье описывается решение только статической задачи.
Описание алгоритма HEngine для статической задачи
Данная реализация фокусируется на поиске строк в пределах k <= 10.
Существует три решения статической задачи: линейный поиск (linear scan), расширение запроса (query expansion) и расширение базы данных (table expansion).
В данном случае под расширением запроса
имеется в виду генерация всех возможных вариантов строк, которые вписываются в заданное расстояние для первоначальной строки.
Расширение базы
данных подразумевает создание множества копий этой базы данных, где или также генерируются все возможные варианты, которые отвечают требованиям необходимого расстояния, либо данные обрабатываются каким-то другим способом (подробно об этом чуть дальше.).
HEngine использует комбинацию этих трех методов для эффективного балансирования между памятью и временем исполнения.
Немного теории
Алгоритм базируется на небольшой теореме, которая гласит следующее:
Если для двух строк a
и b
расстояние HD(a
, b
) <= k
, то если поделить строки a
и b
на подстроки методом rcut
используя фактор сегментации
r
>= ⌊k
/2⌋ + 1
обязательно найдется по крайней мере q
= r
− ⌊k
/2⌋ подстрок, когда их расстояние не будет превышать единицу, HD(a
i, b
i) <= 1.
Выделение подстрок из базовой строки методом rcut
выполняется по следующим принципам:
Выбирается значение, названное фактором сегментации
, которое удовлетворяет условию
r
>= ⌊k
/2⌋ + 1
Длина первых r − (m mod r ) подстрок будет иметь длину ⌊m / r ⌋, а последние m mod r подстроки ⌈m /r ⌉. Где m - это длина строки, ⌊ - округление до ближайшего снизу, а ⌉ округление до ближайшего сверху.
Теперь тоже самое, только на примере:
Даны две бинарные строки длиной m
= 8 бит: A = 11110000 и B = 11010001, расстояние между ними k
= 2.
Выбираем фактор сегментации r
= 2 / 2 + 1 = 2, т. е. всего будет 2 подстроки длиной m
/r
= 4 бита.
a1 = 1111, a2 = 0000
b1 = 1101, b2 = 0001
Если мы сейчас подсчитаем расстояние между соответствующими подстроками, то по крайней мере q = 2 - 2/2 = 1, одна подстрока совпадет или их расстояние не будет превышать единицу.
Что и видим:
HD(a1, b1) = HD(1111, 1101) = 1
и
HD(a2, b2) = HD(0000, 0001) = 1
Подстроки базовой строки были названы сигнатурами
.
Сигнатуры или подстроки a1 и b1 (a2 и b2, a3 и b3 …, ar
и br
) называются совместимыми
с друг другом, а если их количество отличающихся битов не больше единицы, то эти сигнатуры называются совпадающими
.
И главная идея алгоритма HEngine - это подготовить базу данных таким образом, чтобы найти совпадающие сигнатуры и затем выбрать те строки, которые находятся в пределах требуемого расстояния Хэмминга.
Предварительная обработка базы данных
Нам уже известно, что если правильно поделить строку на подстроки, то, по крайней мере, одна подстрока совпадет с соответствующей подстрокой либо количество отличающихся битов не будет превышать единицу (сигнатуры совпадут).
Это означает, что нам не надо проводить полный перебор по всем строкам из базы данных, а требуется сначала найти те сигнатуры, которые совпадут, т.е. подстроки будут отличаться максимум на единицу.
Но как производить поиск по подстрокам?
Метод двоичного поиска должен неплохо с этим справляться. Но он требует, чтобы список строк был отсортирован. Но у нас получается несколько подстрок из одной строки. Что бы произвести двоичный поиск по списку подстрок, надо чтобы каждый такой список был отсортирован заранее.
Поэтому здесь напрашивается метод расширения базы данных, т. е. созданию нескольких таблиц, каждая для своей подстроки или сигнатуры. (Такая таблица называется таблицей сигнатур
. А совокупность таких таблиц - набор сигнатур
).
В оригинальной версии алгоритма еще описывается перестановка подстрок таким образом, чтобы выбранные подстроки были на первом месте. Это делается больше для удобства реализации и для дальнейших оптимизаций алгоритма:
Имеется строка A, которая делится на 3 подстроки, a1, a2, a3, полный список перестановок будет соответственно:
a1, a2, a3
a2, a1, a3
a3, a1, a2
Затем эти таблицы сигнатур сортируются.
Реализация поиска
На этом этапе, после предварительной обработки базы данных мы имеем несколько копий отсортированных таблиц, каждая для своей подстроки.
Очевидно, что если мы хотим сперва найти подстроки, необходимо из запрашиваемой строки получить сигнатуры тем же способом, который был использован при создании таблиц сигнатур.
Так же нам известно, что необходимые подстроки отличаются максимум на один элемент. И чтобы найти их потребуется воспользоваться методом расширения запроса (query expansion).
Другими словами требуется для выбранной подстроки сгенерировать все комбинации включая саму эту подстроку, при которых различие будет максимум на один элемент. Количество таких комбинаций будет равна длине подстроки + 1.
Такие действия надо произвести для всех подстрок и для всех таблиц.
И в самом конце потребуется отфильтровать те строки, которые не вмещаются в заданный предел расстояния Хэмминга. Т.е. произвести линейный поиск по найденным строкам и оставить только те строки, которые отвечают условию HD(a , b ) <= k .
Фильтр Блума
Если перед двоичным поиском подстроки в таблице фильтр возвращает, что эта подстрока не находится в этой таблице, то нет смысла производить поиск.
Соответственно надо создать по одному фильтру на каждую таблицу сигнатур.
Авторы также отмечают, что использование фильтра Блума таким способом снижает время обработки запросов в среднем на 57.8%. На моих тестовых выборках такой фильтр практически не влияет на результирующее время работы. Ощутим только на случайным образом сгенерированной базе данных.
Теперь тоже самое, только на примере
Имеется база данных бинарных строк длиной 8 бит:
11111111
10000001
00111110
Задача найти все строки, где количество отличающихся битов не превышает 2 к целевой строке 10111111.
Значит требуемое расстояние k = 2.
1. Выбираем фактор сегментации.
Исходя из формулы, выбираем фактор сегментации r = 2 и значит всего будет две подстроки из одной строки.
2. Создаем набор сигнатур.
Так как количество подстрок 2, то требуется создать только 2 таблицы:
3. Сохраняем подстроки в соответствующих таблицах с сохранением ссылки на первоисточник.
Т1 Т2
1111 1111 => 11111111
1000 0001 => 10000001
0011 1110 => 00111110
4. Сортируем таблицы. Каждую в отдельности.
Т1
0011 => 00111110
1000 => 10000001
1111 => 11111111
Т2
0001 => 10000001
1110 => 00111110
1111=> 11111111
На этом предварительная обработка закончена. И приступаем к поиску.
5. Получаем сигнатуры запрашиваемой строки.
Искомая строка 10111110 разбивается на сигнатуры. Получается 1011 и 1100, соответственно первая для первой таблицы, а вторая для второй.
6. Генерируем все комбинации отличающихся на единицу.
Количество вариантов будет 5.
6.1 Для первой подстроки 1011:
1011
0
011
11
11
100
1
1010
6.2 Для второй подстроки 1100:
1100
0
100
10
00
111
0
1101
7. Двоичный поиск.
7.1 Для всех сгенерированных вариантов первой подстроки 1011 производим двоичный поиск в первой таблице на полное совпадение.
1011
0011 == 0011 => 00111110
1111 == 1111 => 11111111
1001
1010
Найдено две подстроки.
7.2 Теперь для всех вариантов второй подстроки 1100 производим двоичный поиск во второй таблице.
1100
0100
1000
1110 == 1110 => 00111110
1101
Найдена одна подстрока.
8. Объедением результаты в один список:
00111110
11111111
9. Линейно проверяем на соответствие и отфильтровываем неподходящие по условию <= 2:
HD(10111110, 00111110) = 1
HD(10111110, 11111111) = 2
Обе строки удовлетворяют условию различия не больше двух элементов.
Хотя на данном этапе и производится линейный поиск, но ожидается, что список строк кандидатов будет совсем не велик.
При условиях, когда число кандидатов будет велико, то предлагается использовать рекурсивный вариант HEngine.
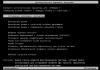
Наглядно
На рисунке №1 показан пример работы алгоритма поиска.
Для длины строки 64 и предел расстояния 4, фактор сегментации равен 3, соответственно только 3 подстроки на строку.
Где T1, T2 и Т3 - это таблицы сигнатур, содержащие только подстроки B1, B2, B3.
Запрашиваемая строка делится на подстроки. Далее для соответствующих подстрок генерируются диапазон сигнатур. И вконце производится двоичный поиск.
Рис 1. Упращенная версия обработки запросов к таблицам сигнатур.
Результаты
Сложность подобного алгоритма в среднем случае O
(m
(log n
+ 1)), где n
- это общее число строк в базе данных, m
- количество двоичных поисков, а log n
+ 1 двоичный поиск.
В экстремальных случаях может превышать линейную. Например, при условии q
= 1 и когда все строки из всех таблицы сигнатур, кроме последней, совпадают с запрашиваемой, то получается O
((r
- 1)m
n
(log n
+ 1)).
Отмечается, что такой подход использует в 4.65 меньше памяти и на 16 % быстрее, чем предыдущая работа описанная в .
Реализация
Все это конечно заманчиво, но пока не потрогаешь на деле, тяжело оценить масштабы.
Был создан прототип HEngine и протестирован на имеющихся реальных данных.
Tests$ ./matches 7 data/db/table.txt data/query/face2.txt Reading the dataset ........ done. 752420 db hashes and 343 query hashes. Building with 7 hamming distance bound ....... done. Building time: 12.964 seconds Searching HEngine matches ....... found 100 total matches. HEngine query time: 0.228 seconds Searching linear matches ....... found 100 total matches. Linear query time: 6.828 seconds
Результаты обрадовали, т. к. поиск 343 хеша из базы в 752420 занимает ~0.2 секунды, что в 30 раз быстрее линейного поиска.
Казалось бы тут можно было остановиться. Но уж больно хотелось попробовать это использовать как-то в реальном проекте.
В один клик до реального применения
Имеется база данных хешей изображений, и бекенд на PHP.
Задача стояла как-то связать функциональность HEngine и PHP.
Решено было использовать FastCGI , в этом мне сильно помогли посты habrahabr.ru/post/154187/ и habrahabr.ru/post/61532/ .
Из PHP достаточно вызвать:
$list = file_get_contents("http://fcgi.local/?" . $hashes);
Что за примерно 0.5 секунды возвращает результат. Когда линейным поиском требуется 9 сек, а через запросы к MySQL не меньше 20 секунд.
Спасибо всем, кто осилил.
- Tutorial
В данной статье речь пойдет об алгоритме HEngine и реализации решения проблемы подсчета расстояния Хэмминга на больших объемах данных.
Введение
Расстояние Хэмминга - это количество различающихся позиций для строк с одинаковой длинной. Например, HD(1 00 , 0 01 ) = 2.Впервые проблема подсчета расстояния Хэмминга была поставлена Minsky и Papert в 1969 году , где задача сводилась к поиску всех строк из базы данных, которые находятся в пределах заданного расстояния Хэмминга к запрашиваемой.
Подобная задача является необычайно простой, но поиск ее эффективного решения до сих пор остается на повестке дня.
Расстояние Хэмминга уже довольно широко используется для различных задач, таких как поиск близких дубликатов, распознавание образов, классификация документов, исправление ошибок, обнаружения вирусов и т.д.
Например, Manku и сотоварищи предложили решение проблемы кластеризации дубликатов при индексации веб документов на основе подсчета расстояния Хэмминга .
Также Miller и друзья предложили концепцию поиска песен по заданному аудио фрагменту , .
Подобные решения были использованы и для задачи поиска изображений и распознавание сетчатки , и т.д.
Описание проблемы
Имеется база данных бинарных строк T , размером n , где длина каждой строки m . Запрашиваемая строка a и требуемое расстояние Хэмминга k .Задача сводится к поиску всех строк, которые находятся в пределах расстояния k .
В оригинальной концепции алгоритма рассматривается два варианта задачи: статическая и динамическая.
В статической задачи расстояние k предопределено заранее.
- В динамической, наоборот, требуемое расстояние заранее неизвестно.
В статье описывается решение только статической задачи.
Описание алгоритма HEngine для статической задачи
Данная реализация фокусируется на поиске строк в пределах k <= 10.Существует три решения статической задачи: линейный поиск (linear scan), расширение запроса (query expansion) и расширение базы данных (table expansion).
В данном случае под расширением запроса
имеется в виду генерация всех возможных вариантов строк, которые вписываются в заданное расстояние для первоначальной строки.
Расширение базы
данных подразумевает создание множества копий этой базы данных, где или также генерируются все возможные варианты, которые отвечают требованиям необходимого расстояния, либо данные обрабатываются каким-то другим способом (подробно об этом чуть дальше.).
HEngine использует комбинацию этих трех методов для эффективного балансирования между памятью и временем исполнения.
Немного теории
Алгоритм базируется на небольшой теореме, которая гласит следующее:Если для двух строк a
и b
расстояние HD(a
, b
) <= k
, то если поделить строки a
и b
на подстроки методом rcut
используя фактор сегментации
r
>= ⌊k
/2⌋ + 1
обязательно найдется, по крайней мере, q
= r
− ⌊k
/2⌋ подстрок, когда их расстояние не будет превышать единицу, HD(a
i, b
i) <= 1.
Выделение подстрок из базовой строки методом rcut
выполняется по следующим принципам:
Выбирается значение, названное фактором сегментации
, которое удовлетворяет условию
r
>= ⌊k
/2⌋ + 1
Длина первых r − (m mod r ) подстрок будет иметь длину ⌊m / r ⌋, а последние m mod r подстроки ⌈m /r ⌉. Где m - это длина строки, ⌊ - округление до ближайшего снизу, а ⌉ округление до ближайшего сверху.
Теперь тоже самое, только на примере:
Даны две бинарные строки длиной m
= 8 бит: A = 11110000 и B = 11010001, расстояние между ними k
= 2.
Выбираем фактор сегментации r
= 2 / 2 + 1 = 2, т. е. всего будет 2 подстроки длиной m
/r
= 4 бита.
A1 = 1111, a2 = 0000
b1 = 1101, b2 = 0001
Если мы сейчас подсчитаем расстояние между соответствующими подстроками, то, по крайней мере, (q = 2 - 2/2 = 1) одна подстрока совпадет или их расстояние не будет превышать единицу.
Что и видим:
HD(a1, b1) = HD(1111, 1101) = 1
и
HD(a2, b2) = HD(0000, 0001) = 1
Подстроки базовой строки были названы сигнатурами
.
Сигнатуры или подстроки a1 и b1 (a2 и b2, a3 и b3 …, ar
и br
) называются совместимыми
с друг другом, а если их количество отличающихся битов не больше единицы, то эти сигнатуры называются совпадающими
.
И главная идея алгоритма HEngine - это подготовить базу данных таким образом, чтобы найти совпадающие сигнатуры и затем выбрать те строки, которые находятся в пределах требуемого расстояния Хэмминга.
Предварительная обработка базы данных
Нам уже известно, что если правильно поделить строку на подстроки, то, по крайней мере, одна подстрока совпадет с соответствующей подстрокой либо количество отличающихся битов не будет превышать единицу (сигнатуры совпадут).Это означает, что нам не надо проводить полный перебор по всем строкам из базы данных, а требуется сначала найти те сигнатуры, которые совпадут, т.е. подстроки будут отличаться максимум на единицу.
Но как производить поиск по подстрокам?
Метод двоичного поиска должен неплохо с этим справляться. Но он требует, чтобы список строк был отсортирован. Но у нас получается несколько подстрок из одной строки. Что бы произвести двоичный поиск по списку подстрок, надо чтобы каждый такой список был отсортирован заранее.
Поэтому здесь напрашивается метод расширения базы данных, т. е. созданию нескольких таблиц, каждая для своей подстроки или сигнатуры. (Такая таблица называется таблицей сигнатур
. А совокупность таких таблиц - набор сигнатур
).
В оригинальной версии алгоритма еще описывается перестановка подстрок таким образом, чтобы выбранные подстроки были на первом месте. Это делается больше для удобства реализации и для дальнейших оптимизаций алгоритма:
Имеется строка A, которая делится на 3 подстроки, a1, a2, a3, полный список перестановок будет соответственно:
a1, a2, a3
a2, a1, a3
a3, a1, a2
Затем эти таблицы сигнатур сортируются.
Реализация поиска
На этом этапе, после предварительной обработки базы данных мы имеем несколько копий отсортированных таблиц, каждая для своей подстроки.Очевидно, что если мы хотим сперва найти подстроки, необходимо из запрашиваемой строки получить сигнатуры тем же способом, который был использован при создании таблиц сигнатур.
Так же нам известно, что необходимые подстроки отличаются максимум на один элемент. И чтобы найти их потребуется воспользоваться методом расширения запроса (query expansion).
Другими словами требуется для выбранной подстроки сгенерировать все комбинации включая саму эту подстроку, при которых различие будет максимум на один элемент. Количество таких комбинаций будет равна длине подстроки + 1.
Такие действия надо произвести для всех подстрок и для всех таблиц.
И в самом конце потребуется отфильтровать те строки, которые не вмещаются в заданный предел расстояния Хэмминга. Т.е. произвести линейный поиск по найденным строкам и оставить только те строки, которые отвечают условию HD(a , b ) <= k .
Фильтр Блума
Авторы предлагают использовать фильтр Блума для уменьшения количества двоичных поисков.Фильтр Блума может быстро определить находится ли подстрока в таблице с небольшим процентом ложных срабатываний. Что работает быстрее, чем хеш таблицы.
Если перед двоичным поиском подстроки в таблице фильтр возвращает, что эта подстрока не находится в этой таблице, то нет смысла производить поиск.
Соответственно надо создать по одному фильтру на каждую таблицу сигнатур.
Теперь тоже самое, только на примере
Имеется база данных бинарных строк длиной 8 бит:11111111
10000001
00111110
Задача найти все строки, где количество отличающихся битов не превышает 2 к целевой строке 10111111.
Значит требуемое расстояние k
= 2.
1. Выбираем фактор сегментации.
Исходя из формулы, выбираем фактор сегментации r
= 2 и значит всего будет две подстроки из одной строки.
2. Создаем набор сигнатур.
Так как количество подстрок 2, то требуется создать только 2 таблицы:
Т1 и Т2
3. Сохраняем подстроки в соответствующих таблицах с сохранением ссылки на первоисточник.
Т1 Т2
1111 1111 => 11111111
1000 0001 => 10000001
0011 1110 => 00111110
4. Сортируем таблицы. Каждую в отдельности.
Т1
0011 => 00111110
1000 => 10000001
1111 => 11111111
Т2
0001 => 10000001
1110 => 00111110
1111=> 11111111
На этом предварительная обработка закончена. И приступаем к поиску.
1. Получаем сигнатуры запрашиваемой строки.
Искомая строка 10111110 разбивается на сигнатуры. Получается 1011 и 1100, соответственно первая для первой таблицы, а вторая для второй.
2. Генерируем все комбинации отличающихся на единицу.
Количество вариантов будет 5.
2.1 Для первой подстроки 1011:
1011
0
011
11
11
100
1
1010
2.2 Для второй подстроки 1100:
1100
0
100
10
00
111
0
1101
3. Двоичный поиск.
3.1 Для всех сгенерированных вариантов первой подстроки 1011 производим двоичный поиск в первой таблице на полное совпадение.
1011
0011 == 0011 => 00111110
1111 == 1111 => 11111111
1001
1010
Найдено две подстроки.
3.2 Теперь для всех вариантов второй подстроки 1100 производим двоичный поиск во второй таблице.
1100
0100
1000
1110 == 1110 => 00111110
1101
Найдена одна подстрока.
4. Объедением результаты в один список:
00111110
11111111
5. Линейно проверяем на соответствие и отфильтровываем неподходящие по условию <= 2:
HD(10111110, 00111110) = 1
HD(10111110, 11111111) = 2
Обе строки удовлетворяют условию различия не больше двух элементов.
Хотя на данном этапе и производится линейный поиск, но ожидается, что список строк кандидатов будет совсем не велик.
При условиях, когда число кандидатов будет велико, то предлагается использовать рекурсивный вариант HEngine.
Наглядно
На рисунке №1 показан пример работы алгоритма поиска.Для длины строки 64 и предел расстояния 4, фактор сегментации равен 3, соответственно только 3 подстроки на строку.
Где T1, T2 и Т3 - это таблицы сигнатур, содержащие только подстроки B1, B2, B3, длинной 21, 21 и 22 бита.
Запрашиваемая строка делится на подстроки. Далее для соответствующих подстрок генерируются диапазон сигнатур. Для первой и второй сигнатуры количество комбинаций будет 22. А последняя сигнатура дает 23 варианта. И вконце производится двоичный поиск.
Рис 1. Упращенная версия обработки запросов к таблицам сигнатур.
Результаты
Сложность подобного алгоритма в среднем случае O (P * (log n + 1)), где n - это общее число строк в базе данных, log n + 1 двоичный поиск, а P - количество двоичных поисков: считается, в нашем случае, как количество комбинаций на таблицу умнеженное на количество таблиц: P = (64 / r + 1) * rВ экстремальных случаях сложность может превышать линейную.
Отмечается, что такой подход использует в 4.65 меньше памяти и на 16 % быстрее, чем предыдущая работа описанная в . И является самым быстрым способом из ныне известных, чтобы найти все строки в заданном пределе.
Реализация
Все это конечно заманчиво, но пока не потрогаешь на деле, тяжело оценить масштабы.Был создан прототип HEngine и протестирован на имеющихся реальных данных.
Tests$ ./matches 7 data/db/table.txt data/query/face2.txt Reading the dataset ........ done. 752420 db hashes and 343 query hashes. Building with 7 hamming distance bound ....... done. Building time: 12.964 seconds Searching HEngine matches ....... found 100 total matches. HEngine query time: 0.1 seconds Searching linear matches ....... found 100 total matches. Linear query time: 6.828 seconds
Результаты обрадовали, т. к. поиск 343 хешей из базы в 752420 занимает ~0.1 секунды, что в 60 раз быстрее линейного поиска.
Казалось бы тут можно было остановиться. Но уж больно хотелось попробовать это использовать как-то в реальном проекте.
Из PHP достаточно вызвать:
$list = file_get_contents("http://fcgi.local/?" . $hashes);
Что за ~0.5 секунды возвращает результат. Когда линейным поиском требуется 9 секунд, а через запросы к MySQL не меньше 20 секунд.
Спасибо всем, кто осилил.
Ссылки
M. Minsky and S. Papert. Perceptrons. MIT Press, Cambridge, MA, 1969.G. S. Manku, A. Jain, and A. D. Sarma. Detecting nearduplicates for web crawling. In Proc. 16Th WWW, May 2007.
M. L. Miller, M. A. Rodriguez, and I. J. Cox. Audio fingerprinting: Nearest neighbor search in high-dimensional binary space. In MMSP, 2002.
M. L. Miller, M. A. Rodriguez, and I. J. Cox. Audio fingerprinting: nearest neighbor search in high dimensional binary spaces. Journal of VLSI Signal Processing, Springer, 41(3):285–291, 2005.
J. Landr ́e and F. Truchetet. Image retrieval with binary hamming distance. In Proc. 2nd VISAPP, 2007.
H. Yang and Y. Wang. A LBP-based face recognition method with hamming distance constraint. In Proc. Fourth ICIG, 2007.
B. Bloom. Space/time trade-offs in hash coding with allowable errors. Communications of ACM, 13(7):422–426, 1970.
Alex X. Liu, Ke Shen, Eric Torng. Large Scale Hamming Distance Query Processing. ICDE Conference, pages 553 - 564, 2011.
github.com/valbok/HEngine Моя реализация HEngine на С++ Добавить метки
В книге Стефана Цвейга “Звездные часы человечества” есть замечательный рассказ “Гений одной ночи” об офицере французской армии Руже де Лиле, написавшем в течение одной ночи в пылу охватившего его вдохновения знаменитую “Марсельезу”. Это было в 1792 г. в революционном Марселе. Песня в течение нескольких дней распространилась по Франции, быстро приобрела колоссальную популярность во всём мире и впоследствии стала национальным гимном Французской республики. История сохранила имя Руже в памяти потомства благодаря этой единственной песне.
По аналогии Ричарда Хэмминга можно назвать “гением одной идеи”. Он сформулировал ее в 1950 г. в своей единственной научной статье, посвящённой кодам для коррекции ошибок. Статья содержала конструкцию блочного кода, корректирующего одиночные ошибки, которые возникают при передаче сообщений.
Ричард Хэмминг постоянно вел активные научные исследования, однако знаменитой стала его единственная работа в области теории информации, составляющая по своему объему ничтожный процент его научного творчества. Эта статья быстро получила мировую известность и принесла ему заслуженную славу.
Подобно тому, как вслед за открытиями Фарадея и Максвелла последовали многочисленные изобретения в области электросвязи, изменившие нашу жизнь, так и после создания Клодом Шенноном теории информации и Владимиром Котельниковым теории потенциальной помехоустойчивости открылись новые возможности для развития телекоммуникаций. Одним из важнейших разделов теории информации является теория кодирования, основы которой были заложены Хэммингом.
Шеннон установил, что по каналу связи информация может передаваться безошибочно в том случае, если скорость передачи не превышает его пропускной способности. Однако доказательство Шеннона носило неконструктивный характер. Более поздние его исследования и другого американского ученого С. О. Райса показали, что практически любой случайно выбранный код позволяет достичь теоретического предела помехоустойчивости приёма сообщений. Однако такой код имел высокую сложность декодирования: число операций, необходимых для декодирования принятой кодовой комбинации, возрастал экспоненциально росту его длины.
Хэмминг был первым, кто предложил конструктивный метод построения кодов с избыточностью и простым декодированием. Его труд предопределил направление большинства работ в этой области, последовавших позже.
В его честь Институт инженеров по электротехнике и электронике учредил медаль, которой награждаются ученые, внесшие значительный вклад в теорию информации.
Коды, способные корректировать ошибки (в каналах связи в цифровых вычислительных машинах и т. п.) при обработке сигналов, были предложены Хэммингом еще до 1948 г., когда была опубликована знаменитая статья Шеннона “Математическая теория связи”, заложившая прочную основу теории в данной области.
В этой статье Шеннон, ссылаясь на исследование, выполненное в 1947 г. его сослуживцем по лаборатории Белла Ричардом Хэммингом, описал в качестве примера простой код длины 7, корректирующий все одиночные ошибки. Публикация же оригинального материала Хэмминга по патентным соображениям была задержана до апреля 1950-го. Следует отметить, что пример корректирующего ошибки кода, приведенный в упомянутой статье Шеннона, инициировал исследование другого американского ученого, М. Е. Голея. Голей независимо от Хэмминга открыл коды, корректирующие одиночные ошибки. В 1949 г. (т. е. раньше Хэмминга) он опубликовал короткую заметку (всего на полстраницы) о своих результатах в Трудах IЕЕE. В этой заметке он рассмотрел не только бинарные коды, но и коды общего вида, комбинации которых принадлежат конечному полю (математическому множеству элементов с определенными операциями сложения, вычитания, деления и умножения) с рn элементами (р – простое, а n – целое число).
Надо отметить, что ряд основополагающих идей теории связи был известен в качестве частных математических результатов ещё до того, как их начали применять учёные, решающие проблемы передачи сообщений по каналам связи. В своей книге “Алгебраическая теория кодирования” крупный американский специалист в области теории кодирования Э. Берлекамп сделал весьма интересное замечание. Он отметил, что конструкция кодов Хэмминга была описана в ином контексте ещё в 1942 г. известным американским математиком Р. А. Фишером, в работе посвященной теории факторного анализа (одного из разделов математической статистики) и её связи с математической теорией групп. Кстати, теорема В. А. Котельникова, указывающая на возможность представления аналоговых сигналов в цифровом виде, тоже была открыта как один из частных математических результатов теории интерполяции функции ещё в начале ХХ века английскими математиками Е. Т. и Дж. М. Уиткерами. Следует подчеркнуть, что ни Фишер, ни упомянутые английские ученые не связывали свои результаты с важнейшими для современного мира проблемами передачи информации по каналам связи.
Вольфганг Гёте говорил: “Недостаточно только получить знание; надо найти ему приложение. Недостаточно только желать; надо делать”. Для теории и техники... связи теорема Котельникова и коды Хэмминга имеют исключительное значение, поскольку именно благодаря им перед инженерами открылась ясная перспектива создания цифровых систем, которые в конце ХХ века произвели революцию в электросвязи и поэтому их с полным основанием называют именами этих учёных.
Став катализатором, ускорившим развитие теории кодирования, статья Хэмминга обратила на себя внимание научной общественности. Во всех учебниках этот класс кодов называют кодами Хэмминга и изложение теории кодирования начинают с описания их конструкции. По-видимому, всё же было бы справедливее эти коды называть кодами Хэмминга – Голея, учитывая, что Голей пришёл к тем же идеям, что и Хэмминг, независимо и опубликовал их раньше. То, что его статья не вызвала к себе должного внимания, скорее всего, является волей случая.
По сравнению с теорией Шеннона коды, введенные Хэммингом, были разочаровывающе слабы. Однако предложенные Хэммингом регулярные методы построения кодов, корректирующих ошибки, имели фундаментальное значение. Они продемонстрировали инженерам практическую возможность достижения тех пределов, на которую указывали законы теории информации. Эти коды нашли практическое применение при создании компьютерных систем. Статья Хэмминга привела также к решению проблемы более плотной упаковки для конечных полей. Он ввел в научный обиход важнейшие понятия теории кодирования – расстояние Хэмминга между кодовыми комбинациями в векторном пространстве, определяемом для двоичных кодов как количество позиций этих комбинаций с различными символами, и границы Хэмминга для исправляющей способности блочных корректирующих кодов. Граница Хэмминга для двоичных кодов рассчитывается по следующей формуле:
В этом выражении число ошибок e может быть исправлено корректирующим блочным кодом длиной N, имеющим М кодовых комбинаций (CjN – биномиальный коэффициент).
Работа Хэмминга сыграла ключевую роль в последующем развитии теории кодирования и стимулировала обширные исследования, выполненные в последующие годы. В 1956 г. Давид Слепян первым изложил теорию кодов с проверкой четности на серьезной математической основе. Главный сдвиг в области теории кодирования произошел, когда французский ученый А. Хоквингем (1959 г.) и американцы Р. К. Боуз и Д. К. Рой-Чоудхури (1960 г.) нашли большой класс кодов (коды БЧХ), исправляющих кратные ошибки. Американские исследователи И. С. Рид и Г. Соломон (1960 г.) нашли связанный с кодами БЧХ класс кодов для недвоичных каналов.
В 1980 г. Хэмминг написал блестящий учебник “Теория кодирования и теория информации”, который в 1983 г. был переведен на русский язык. Эту книгу, как и другие его труды, отличает оригинальность постановки вопросов, популярность изложения, глубокое понимание практических задач, корректность и разумная степень строгости математической трактовки затронутых вопросов. Изложение материала построено таким образом, что читателю интуитивно понятно, почему справедлива та или иная теорема
Cтраница 1
Расстояние Хемминга между двумя последовательностями равной длины соответствует числу позиций, занятых несовпадающими элементами. В случае последовательностей различной длины расстояние Хэмминга определяется как минимальное число позиций, занятых несовпадающими элементами при.
Расстояние Хемминга d (u, v) между двумя словами и и v одинаковой длины равно числу несовпадающих разрядов этих слов. Оно используется в теории блочных кодов (В.
С использованием метрических свойств расстояния Хемминга непосредственно проверяется, что / л является метрикой на Хц, но не является метрикой на множестве смешанно-периодических последовательностей.
Эта функция близости эквивалентна расстоянию Хемминга.
Метрика р в алгоритме KLOP задана расстоянием Хемминга.
Если процедура поиска сможет найти положение, где расстояние Хемминга равно нулю, задача будет решена.
Сопоставление нечетких подмножеств В и В3, степеней нечеткости, а также расстояния Хемминга показывает, что рассматриваемые нечеткие подмножества отличаются. Однако если в качестве рассчитанного значения принимать элемент м2 G Uz, степень принадлежности которого полученному нечеткому подмножеству максимальна, то применение нечеткого отношения R, вычисленного таким способом, может быть оправдано. Наряду с тем, что при данном подходе удается описать нелинейность связи между максимальной температурой во второй зоне реактора и показателем текучести расплава полиэтилена, этот способ не учитывает нестационарность процесса получения ПЭВД, которая связана с изменением характеристик технологического процесса.
Передаточная функция этого кода указывает на то, что имеется единственный путь с расстоянием Хемминга d - от пути из одних нулей, который сливается с путем из одних нулей при данном узле. Из диаграммы состояний, показанной на рис. 8.2.6, или решетчатой диаграммы, показанной на рис. 8.2.5, видно, что путь с d6 это acbe. Снова из диаграммы состояний или решетки мы видим, что этими путями являются acdbe и acbcbe. Третье слагаемое в (8.1.2) указывает, что есть четыре пути с расстоянием d 0 и так далее. Таким образом, передаточная функция дает нам дистанционные свойства сверточного кода.
Этот результат согласуется с наблюдением, что путь из одних нулей (/ 0) имеет расстояние Хемминга d3 от принимаемой последовательности, в то время как путь с / 1 имеет расстояние Хемминга d5 от принимаемого пути. Таким образом, расстояние Хемминга является эквивалентной метрикой для декодирования с жестким решением.
Этот результат согласуется с наблюдением, что путь из одних нулей (/ 0) имеет расстояние Хемминга d3 от принимаемой последовательности, в то время как путь с / 1 имеет расстояние Хемминга d5 от принимаемого пути. Таким образом, расстояние Хемминга является эквивалентной метрикой для декодирования с жестким решением.
) в векторном пространстве кодовых последовательностей, в этом случае расстоянием Хэмминга между двумя двоичными последовательностями (векторами) и длины называется число позиций, в которых они различны - в такой формулировке расстояние Хэмминга вошло в Словарь алгоритмов и структур данных Национального Института Стандартов США (англ. NIST Dictionary of Algorithms and Data Structures ).
Так, расстояние Хэмминга между векторами 0 011 1 и 1 010 1 равно 2 (красным отмечены различающиеся биты). В дальнейшем метрика была обобщена на q-ичные последовательности: для пары строк «вы боры » и «за бора » расстояние Хэмминга равно трём.
В общем виде расстояние Хэмминга для объектов и размерности задаётся функцией:

Расстояние Хэмминга обладает свойствами метрики, удовлетворяя следующим условиям:
Расстояние Хэмминга в биоинформатике и геномике
Литература
- Richard W. Hamming . Error-detecting and error-correcting codes, Bell System Technical Journal 29(2):147-160, 1950.
- Ричард Блейхут . Теория и практика кодов, контролирующих ошибки. М., «Мир», 1986
Ссылки
- Ричард Хэмминг и начало теории кодирования // Виртуальный компьютерный музей
Wikimedia Foundation . 2010 .
Смотреть что такое "Расстояние Хемминга" в других словарях:
расстояние Хемминга - хемминговское расстояние Расстояние d (u,v) между двумя кодовыми последовательноаями u и v одинаковой длины, равное числу символов, в которых они отличаются. Блочный код с минимальным хемминговским расстоянием d позволяет обнаружить (d 1) и… …
кодовое расстояние - Минимум расстояния Хемминга, взятый по всем ларам различных кодовых слов в равномерном коде. [Сборник рекомендуемых терминов. Выпуск 94. Теория передачи информации. Академия наук СССР. Комитет технической терминологии. 1979 г.] Тематики теория… … Справочник технического переводчика
В области математики и теории информации линейный код это важный тип блокового кода, использующийся в схемах определения и коррекции ошибок. Линейные коды, по сравнению с другими кодами, позволяют реализовывать более эффективные алгоритмы… … Википедия
В области математики и теории информации линейный код это важный тип блокового кода, использующийся в схемах определения и коррекции ошибок. Линейные коды, по сравнению с другими кодами, позволяют реализовывать более эффективные алгоритмы… … Википедия
Обнаружение ошибок в технике связи действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) процедура восстановления… … Википедия
Обнаружение ошибок в технике связи действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) процедура восстановления информации после… … Википедия
Обнаружение ошибок в технике связи действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) процедура восстановления информации после… … Википедия
Обнаружение ошибок в технике связи действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) процедура восстановления информации после… … Википедия