Влад Мержевич
Метатеги используются для хранения информации предназначенной для браузеров и поисковых систем. Например, механизмы поисковых систем обращаются к метатегам для получения описания сайта, ключевых слов и других данных.
Метатеги для поисковых механизмов
Среди разработчиков сайтов существует мнение, что правильно написанные метатеги позволяют подняться к верхним строчкам поисковых серверов. На самом деле это не так, на одних метатегах высоко не поднимешься, но и неудачно выполненное содержимое метатегов может ухудшить рейтинг сайта.
Два метатега предназначены специально для поисковых серверов: description (описание) и keywords (ключевые слова). Некоторые вебмастера добавляли в раздел keywords ключевые слова, которые не имеют никакого отношения к теме сайта, но зато пользовались определенным успехом среди посетителей поисковиков. Однако, через некоторое время, поисковые системы научились бороться с таким явлением и проверяют содержимое веб-страницы на соответствие заявленным ключевым словам.
Некоторые принципы, относящиеся к метатегам:
- не включайте ключевые слова, которые не содержатся на ваших страницах;
- не повторяйте ключевые слова;
- используйте метатеги по их прямому назначению;
- делайте описание и список ключевых слов различными для каждой страницы сайта с учетом содержимого.
description
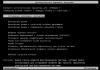
Большинство поисковых серверов отображают содержимое поля description (пример 1) при выводе результатов поиска. Если этого тега нет на странице, то поисковый движок просто перечислит первые встречающиеся слова на странице, которые, как правило, оказываются не очень-то и в тему.
Пример 1. Использование Description
keywords
Этот метатег был предназначен для описания ключевых слов, встречающихся на странице (пример 2). Но в результате действия людей, желающих попасть в верхние строчки поисковых систем любыми средствами, теперь дискредитирован. Поэтому многие поисковики пропускают этот параметр.
Пример 2. Использование Keywords
Ключевые слова можно перечислять через пробел или запятую. Поисковые системы сами приведут запись к виду, который они используют.
Автозагрузка страниц
Чтобы автоматически загружать новый документ через определенный промежуток времени используется инструкция http-equiv="refresh" (пример 3).
. Для операционной системы Windows и кириллицы charset обычно принимает значение utf-8 или windows-1251 (пример 4).
Пример 4. Выбор текущей кодировки
Кириллица
Если указание кодировки отсутствует, браузер пытается сам определить, какой тип символов используется в документе и выбирает необходимую кодировку автоматически. Браузер не всегда может точно распознать язык веб-страницы и в некоторых случаях предлагает вьетнамскую кодировку вместо кириллицы. По этой причине лучше всегда указывать приведенную строчку. Тем не менее, возникают обстоятельства, когда указание кодировки может принести определенный вред. Например, веб-сервер автоматически использует перекодирование данных в KOI-8, а браузер, встретив параметр charset=windows-1251 , переводит текст в кодировку Windows. Получается двойное изменение символов, прочитать такой текст не просто. К счастью, подобная проблема уже отходит в прошлое, во всяком случае, ее легко можно выявить и нейтрализовать на уровне сервера.
Практический каждый новичок в области веб-разработок, рано или поздно сталкивается с проблемами кодировки в своих проектах. И тогда, как по написанному сценарию, начинается бомбардировка форумов с вопросами о том, как победить ненавистные "кракозябры ". Подавляющее большинство проблем уже давно известны и лечатся довольно легко, нужно просто знать "в каком месте болит и какую таблетку принять ". Посему, предлагаю разобрать наиболее популярные ошибки, из-за которых эта проблемка появляется и возможно, что мои рекомендации избавят вас от дальнейших с ними столкновений.
Во-первых, настоятельно рекомендую, чтобы все документы были в одной кодировке и база данных, а именно поля со строковыми данными, имели такую же кодировку. Устанавливается она при создании базы или же можно указывать сравнение для каждого отдельного поля. Если создаёте БД с помощью phpMyAdmin, то сложностей возникнуть не должно: закладка "Базы данных" > в поле под "Создать базу данных" вписываете имя вашей будущей БД > рядом выпадающий список "Сравнения". Если же создаёте базу sql-запросом, то пишите примерно следующее:
CREATE DATABASE IF NOT EXISTS `my_db_name` CHARACTER SET utf8 COLLATE utf8_general_ci;
Выбор кодировки остаётся за вами, но я бы посоветовал выбрать для документов "UTF-8 без BOM " и сравнение для базы "utf8_general_ci " (юникод многоязычный, регистронезависимый ). Только не забудьте подстраховаться и сделать дамп перед манипуляциями с БД! Не буду здесь расписывать, что такое BOM , но если о-о-очень образно и на пальцах, то это такой невидимый маркер, который планировался для различения кодировок UTF-16LE и UTF-16BE, но по некоторым причинам оказался невостребованным и теперь мешает веб-разработчикам жить спокойно;) Выглядит BOM, как символ U+FEFF и селится в начале документа. А почему всё-таки UTF-8? Вот, хотя бы пара причин... Вы без проблем сможете выводить на экран как кириллицу, так и цитату из стихов Аль-Мутанабби или китайские иероглифы. Всё потому, что в той же кодировке windows-1251 (cp1251) всего лишь 256 символов, в то время, как в UTF-8 их около ста тысяч, плюс ко всему специальные символы, пиктограммы, значки и т.д. Если вы собираетесь использовать на своём сайте ajax-запросы, то это так же добавляет плюс к кодировке UTF-8, потому что именно с этой кодировкой дружит объект XMLHttpRequest, а с другими придётся извращаться и иногда безуспешно. Та же карта сайта (sitemap.xml), которая служит для индексации поисковыми системами, работает только, если этот файл создан с кодировкой UTF-8. Кроме того, эта кодировка является стандартом для работы многих функций PHP и стандартом, который рекомендован W3C .
При создании нового документа - всё ясно, а как быть с уже существующим, в котором желательно изменить кодировку? Один из самых простых способов - это открыть документ в Notepad++ , выбрать в меню "Кодировки " и в списке "Преобразовать в UTF-8 без BOM ". Далее изменяем метатег с определением кодировки:
И для php-файлов можно установить соответствующий заголовок, но только, если файл не подключен в другом документе, где такой заголовок уже будет отправлен раньше. Это касается как заголовка в метатеге, так и отправленного функцией header:
Header("Content-Type: text/html; charset=utf-8");
Проверяем результат в браузере. Тут может несколько вариантов:
- Всё выводится отлично и вопрос закрыт
- Статически прописанные данные отображаются нормально, но данные из БД - всё тами же "кракозябрами"
- Ничего не изменилось и кодировка осталась кривой
Начнём с последнего пункта. Счастливые владельцы выделенных серверов или VPS/VDS, могут изменить кодировку для директивы default_charset в конфигурационном файле php.ini. Тем же, кто доступа к php.ini не имеет или имеет, но необходимо изменить кодировку только для одного сайта, можно использовать файл.htaccess, записав в него следующее:
# в принципе, хватает строки ниже: AddDefaultCharset UTF-8 # но иногда, могут потребоваться дополнительные установки: DefaultLanguage ru php_value default_charset "utf-8"
Файл.htaccess распологается в корне вашего сайта. Если вы его там не обнаружили, то создаём сами. В обычном блокноте создаёте документ > "Сохранить как " > Тип файла выбрать "Все файлы " > в поле "Имя файла" записываем только точку и расширение ".htaccess ".
Переходим ко второму пункту - если базу перевели на нужную кодировку, но данные из неё отображаются на странице криво. Для начала, нужно убедится, что символы в самой базе отображаются нормально. Если кодировка там "не поплыла", то можно или же опять апеллировать к файлам конфигурации, или сделать запрос сразу после подключения к базе:
SET NAMES utf8;
* я пишу сам текст запроса, но т.к. не знаю какое расширение вы используете для работы с MySQL, покажу несколько вариантов:
// для устаревшего mysql_* $db = mysql_connect("localhost", "username", "password"); mysql_select_db("db_name", $db); mysql_query("SET NAMES utf8"); // для PDO и версий php ниже 5.3.6 $dbh = new PDO("mysql:host=localhost;dbname=db_name", "username", "password"); $dbh->exec("SET NAMES utf8"); // для PDO и версий php 5.3.6 и новее, можно указывать прямо при создании объекта $dbh = new PDO("mysql:host=localhost;dbname=db_name;charset=utf8", "username", "password"); // или $db = new PDO("mysql:host=localhost;dbname=db_name", "username", "password", array(PDO::MYSQL_ATTR_INIT_COMMAND => "SET NAMES utf8")); // для MySQLi $mysqli = new mysqli("localhost", "username", "password", "db_name"); $mysqli->set_charset("utf8");
Раз уж затронул вопрос "устаревшего mysql_*", то хочу обратить ваше внимание, на текст выделенный красным в документации php. Cто́ит задуматься...
Если у вас была одна из стандартных проблем, то выполнив некоторые или все вышеописанные шаги, с кодировкой вопрос будет решен положительно. Но так же хотелось бы упомянуть о некоторых функциях, которые могут пригодится в нестандартных ситуациях. Подробнее о них вы сможете прочитать в документации, а я лишь приведу пару примеров, не вдаваясь в подробности:
Mb_internal_encoding() C помощью этой функции, мы можем установить или получить текущую кодировку скрипта: mb_internal_encoding("UTF-8"); // устанавливаем echo mb_internal_encoding(); // без аргумента - получаем mb_http_input() и mb_http_output() Две функции, которые определяют, устанавливают или получают кодировку символов HTTP запроса или вывода: print_r(mb_http_input("I")); // определяем кодировку входных данных http-запроса mb_http_output("UTF-8"); // устанавливаем кодировку для http-вывода echo mb_http_output(); // получаем текущую кодировку символов http-вывода iconv() Функция преобразовывает символы строки в нужную кодировку: echo iconv("utf-8","cp1251","Привет, РјРёСЂ!"); // Привет, мир! mb_convert_encoding() Функция похоже на iconv(), но на мой взгляд лучше, т.к. работает более адекватно. echo mb_convert_encoding("Привет, РјРёСЂ!","cp1251","utf-8"); // Привет, мир!
Да и вообще, не забываем про аналоги функций для работы с многобайтными строками . Чаще всего, они имеют такое же название, но с приставкой mb_ . Разницу ощутить достаточно просто. Возьмём, для примера, функции strlen() и mb_strlen() и проведём эксперимент, измерив длину строки:
// установим внутреннюю кодировку mb_internal_encoding("utf-8"); // для латинских символов разницы нет echo strlen("incode"); // 6 echo mb_strlen("incode"); // 6 // А вот с кириллицей выдает - пичалька echo strlen("инкод"); // 10 echo mb_strlen("инкод"); // 5
Может кому и не нужно объяснять это явление, но для новичков растолкую: кириллица кодируется двумя байтами, а strlen() считает именно количество байт в строке, а не количество букв. Вот и получается, что пять кириллических символов умножить на два - получаем 10. Китайские символы, если я не ошибаюсь, вообще кодируются тремя байтами, поэтому в дальнейшем для таких случаев, чтоб не возникало никаких недорозумений, используйте соответствующие функции.
Повторюсь, что эти решения к часто встречающимся случаям и в подавляющем большинстве, они решают проблему. Но если у вас возникла ситуация, когда всэ эти способы не возымели действия, то пишите сюда, попробуем разобраться вместе и дополним статью новым "рецептом от головной боли" ;) Засим позвольте откланяться.
Одной из самых частых проблем, с которой сталкивается начинающий Web-мастер (да и не только начинающие), это проблемы с кодировкой на сайте . Даже у меня постоянно появляется при создании сайтов "абракадабра ". Но, благо, я прекрасно знаю, как эту проблему решить, поэтому всё привожу в порядок в течение нескольких секунд. И в этой статье я постараюсь научить Вас также быстро решать проблемы, связанные с кодировкой на сайте .
Первое, что стоит отметить, это то, что все проблемы с появлением "абракадабры" связаны с несовпадением кодировки документа и кодировки, выставляемой браузером . Допустим, документ в windows-1251 , а браузер почему-то выставляет UTF-8 . А уже источником такого несовпадения могут быть следующие причины.
Первая причина
Неправильно прописан мета-тег content-type . Будьте внимательны, в нём всегда должна находиться та кодировка, в котором написан Ваш документ.
Вторая причина
Вроде бы, мета-тег прописан так, как Вы хотите, и браузер выставляет именно то, что Вы хотите, но почему-то всё равно с кодировкой проблемы. Здесь, почти наверняка, виновато то, что сам документ имеет отличную кодировку. Если Вы работаете в Notepad++ , то внизу справа есть название кодировки текущего документа (например, ANSI ). Если Вы ставите в мета-теге UTF-8 , а сам документ написан в ANSI , то сделайте преобразование в UTF-8 (через меню "Кодировки " и пункт "Преобразовать в UTF-8 без BOM ").
Третья причина
Четвёртая причина
И, наконец, последняя популярная причина - это проблема с кодировкой в базе данных . Во-первых, убедитесь, что все Ваши таблицы и поля написаны в одной кодировке, которая совпадает с кодировкой остального сайта. Если это не помогло, то сразу после подключения в скрипте выполните следующий запрос:
SET NAMES "utf8"
Вместо "utf8 " может стоять другая кодировка. После этого все данные из базы должны выходить в правильной кодировке.
В данной статье я, надеюсь, разобрал, как минимум, 90% проблем, связанных с появлением "абракадабры" на сайте . Теперь Вы должны расправляться с такой популярной и простой проблемой, как неправильная кодировка, в два счёта.
Позже ASCII
была расширена (изначально она не использовала все 8 бит), поэтому появилась возможность использовать уже не 128, а 256 (2 в 8 степени) различных символов, которые можно закодировать в одном байте информации.
Такое усовершенствование позволило добавлять в кодировку ASCII
символы национальных языков разных стран, помимо уже существующей латиницы.
Вариантов расширенной кодировки ASCII
существует очень много по причине того, что языков в мире тоже немало. Думаю, что многие из вас слышали о такой кодировке, как KOI8 (Код Обмена Информацией, 8 бит) — это тоже расширенная кодировка ASCII
. KOI8 включала в себя цифры, буквы латинского и русского алфавита, а также знаки пунктуации, спецсимволы и псевдографику.
Кодировка ISO
Организация Международных стандартов (International Standards Organization) создала диапазон кодировок для различных алфавитов/языков.
| Кодировка | Описание |
|---|---|
| ISO 8859-1 (Latin-1) | Расширенная латиница, включающая символы большинства западноевропейских языков (английский, датский, ирландский, исландский, испанский, итальянский, немецкий, норвежский, португальский, ретороманский, фарерский, шведский, шотландский (гэльский) и частично голландский, финский, французский), а также некоторых восточноевропейских (албанский) и африканских языков (африкаанс, суахили). В Latin-1 отсутствуют знак евро и заглавная буква Ÿ. Эта кодовая страница считается кодировкой по умолчанию для HTML-документов и сообщений электронной почты. Также этой кодовой странице соответствуют первые 256 символов Юникода. |
| ISO 8859-2 (Latin-2) | Расширенная латиница, включающая символы центральноевропейских и восточноевропейских языков (боснийский, венгерский, польский, словацкий, словенский, хорватский, чешский). В Latin-2, как и в Latin-1, отсутствуют знак евро. |
| ISO 8859-3 (Latin-3) | Расширенная латиница, включающая символы южноевропейских языков (мальтийский, турецкий и эсперанто). |
| ISO 8859-4 (Latin-4) | Расширенная латиница, включающая символы североевропейских языков (гренландский, эстонский, латышский, литовский и саамские языки). |
| ISO 8859-5 (Latin/Cyrillic) | Кириллица, включающая символы славянских языков (белорусский, болгарский, македонский, русский, сербский и частично украинский). |
| ISO 8859-6 (Latin/Arabic) | Символы, используемые в арабском языке. Символы других языков с письмом на основе арабского не поддерживаются. Для корректного отображения текста в кодировке ISO 8859-6 требуется поддержка двунаправленного письма и контекстно-зависимых форм символов. |
| ISO 8859-7 (Latin/Greek) | Символы современного греческого языка. Может использоваться также для записи древнегреческих текстов в монотонической орфографии. |
| ISO 8859-8 (Latin/Hebrew) | Символы современного иврита. Используется в двух вариантах: с логическим порядком следования символов (требует поддержки двунаправленного письма) и с визуальным порядком следования символов. |
| ISO 8859-9 (Latin-5) | Вариант Latin-1, в котором редко используемые символы исландского языка заменены на турецкие. Используется для турецкого и курдского языков. |
| ISO 8859-10 (Latin-6) | Вариант Latin-4, более удобный для скандинавских языков. |
| ISO 8859-11 (Latin/Thai) | Символы тайского языка. |
| ISO 8859-13 (Latin-7) | Вариант Latin-4, более удобный для балтийских языков. |
| ISO 8859-14 (Latin-8) | Расширенная латиница, включающая символы кельтских языков, таких как шотландский (гэльский) и бретонский. |
| ISO 8859-15 (Latin-9) | Вариант Latin-1, в котором редко используемые символы заменены на необходимые для полной поддержки финского, французского и эстонского языков. Кроме того, в Latin-9 был добавлен знак евро. |
| ISO 8859-16 (Latin-10) | Расширенная латиница, включающая символы южноевропейских и восточноевропейских (албанский, венгерский, итальянский, польский, румынский, словенский, хорватский), а также некоторых западноевропейских языков (ирландский в новой орфографии, немецкий, финский, французский). Как и в Latin-9, в Latin-10 был добавлен знак евро. |
Для документов на английском и большинстве других западноевропейских языков, широко поддерживается кодирование ISO-8859-1 .
В HTML ISO-8859-1
является кодировкой по умолчанию (в XHTML и в HTML5 кодировкой по умолчанию является UTF-8).
При использовании кодировки страницы, отличной от ISO-8859-1, вам необходимо указать это в теге
.
Для HTML4:
Для HTML5:
Примером ANSI-кодировки является всем известная Windows-1251 .
Windows-1251
выгодно отличается от других 8 битных кириллических кодировок (таких как CP866 и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только знак ударения). Она также содержит все символы для других славянских языков: украинского, белорусского, сербского, македонского и болгарского.
Ниже приведены десятичные значения символов кодировки Windows-1251
.
Для отображения символов таблицы в HTML-документе воспользуйтесь следующим синтаксисом:
&# + код + ;
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ђ
402 |
Ѓ
403 |
‚
201A |
ѓ
453 |
„
201E |
…
2026 |
†
2020 |
‡
2021 |
€
20AC |
‰
2030 |
Љ
409 |
‹
2039 |
Њ
40A |
Ќ
40C |
Ћ
40B |
Џ
40F |
| 9. |
ђ
452 |
‘
2018 |
’
2019 |
“
201C |
”
201D |
2022 |
–
2013 |
-
2014 |
™
2122 |
љ
459 |
›
203A |
њ
45A |
ќ
45C |
ћ
45B |
џ
45F |
|
| A. |
A0 |
Ў
40E |
ў
45E |
Ј
408 |
¤
A4 |
Ґ
490 |
¦
A6 |
§
A7 |
Ё
401 |
©
A9 |
Є
404 |
«
AB |
¬
AC |
AD |
®
AE |
Ї
407 |
| B. |
°
B0 |
±
B1 |
І
406 |
і
456 |
ґ
491 |
µ
B5 |
¶
B6 |
·
B7 |
ё
451 |
№
2116 |
є
454 |
»
BB |
ј
458 |
Ѕ
405 |
ѕ
455 |
ї
457 |
| C. |
А
410 |
Б
411 |
В
412 |
Г
413 |
Д
414 |
Е
415 |
Ж
416 |
З
417 |
И
418 |
Й
419 |
К
41A |
Л
41B |
М
41C |
Н
41D |
О
41E |
П
41F |
| D. |
Р
420 |
С
421 |
Т
422 |
У
423 |
Ф
424 |
Х
425 |
Ц
426 |
Ч
427 |
Ш
428 |
Щ
429 |
Ъ
42A |
Ы
42B |
Ь
42C |
Э
42D |
Ю
42E |
Я
42F |
| E. |
а
430 |
б
431 |
в
432 |
г
433 |
д
434 |
е
435 |
ж
436 |
з
437 |
и
438 |
й
439 |
к
43A |
л
43B |
м
43C |
н
43D |
о
43E |
п
43F |
| F. |
р
440 |
с
441 |
т
442 |
у
443 |
ф
444 |
х
445 |
ц
446 |
ч
447 |
ш
448 |
щ
449 |
ъ
44A |
ы
44B |
ь
44C |
э
44D |
ю
44E |
я
44F |
Кодировки стандарта UNICODE
Юникод (англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки почти всех письменностей мира, и специальных символов. Представляемые в юникоде символы кодируются целыми числами без знака. Юникод имеет несколько форм представления символов в компьютере: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). (Англ. Unicode transformation format - UTF).
UTF-8
— это в настоящее время распространённая кодировка, которая нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий из символов Unicode с номерами меньше 128 (область с кодами от U+0000 до U+007F), содержит символы набора ASCII
с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F.
Кодировка UTF-8 является универсальной и имеет внушительный резерв на будущее. Это делает ее наиболее удобной кодировкой для использования в интернете.
Please enable JavaScript to view the
Для того, чтобы страницы вашего сайта отображались корректно во всех браузерах и на всевозможных устройствах, нужно позаботиться об установке правильной кодировки. Несоблюдение некоторых условий, о которых мы сегодня расскажем подробно, может привести к тому, что текст превратится в бессмысленный набор символов, прочитать которые просто невозможно (кракозябры).
Почему вместо нормального текста отображаются кракозябры
Каждая страница вашего сайта должна иметь определенную кодировку. О том, какая кодировка используется в данный момент необходимо сообщать браузеру, передавая специальные заголовки (header). В этих заголовках необходимо указать кодировку, соответствующую той, которую вы используете в теле документов, размещенных на сайте (на его страницах).
 Современные браузеры могут и сами определить кодировку документа, если вебмастер забыл указать ее в явном виде. Иногда случается так, что возникают несостыковки между «мнением» браузера и реальностью, отсюда и появляется набор символов, которые невозможно прочитать. Набор галиматьи может принимать разные виды, иногда это будут просто странные символы, похожие на древние иероглифы, а иногда - просто вопросики или же вопросики внутри черных ромбиков. По большому счету не так важно, какие именно кракозябры отображает браузер, а важно то, что человек их прочитать не может.
Современные браузеры могут и сами определить кодировку документа, если вебмастер забыл указать ее в явном виде. Иногда случается так, что возникают несостыковки между «мнением» браузера и реальностью, отсюда и появляется набор символов, которые невозможно прочитать. Набор галиматьи может принимать разные виды, иногда это будут просто странные символы, похожие на древние иероглифы, а иногда - просто вопросики или же вопросики внутри черных ромбиков. По большому счету не так важно, какие именно кракозябры отображает браузер, а важно то, что человек их прочитать не может.
Если же вы столкнулись с проблемой некорректно указанной кодировки и видите на своем сайте то, что не в состоянии прочитать, в первую очередь воспользуйтесь специальным Декодером , разработанным в студии Артемия Лебедева. Для этого просто скопируйте текст, который хотите расшифровать, вставьте его в специальное поле и нажмите «Расшифровать». В случае успешного декодирования, вы увидите уже читаемый текст, а также исходную кодировку и путь, который пришлось пройти программе, чтобы вывести результат.
Все это нужно, скорее, для продвинутых пользователей, которым полученная информация сможет чем-то помочь. Возможно, результат действий программы натолкнет вас на мысль и вы сообразите, откуда на вашем сайте берутся кракозябры и быстро исправите ситуацию. А если же проделанные манипуляции совершенно ни о чем вам не говорят, то давайте просто двигаться дальше.
Как правильно выбрать кодировку
В рамках данной статьи мы не будем углубляться в то, какие кодировки бывают и чем они друг от друга отличаются, т.к. не хотим перегружать ни себя, ни вас лишней информацией, да и в целях сегодняшней статьи этого не было. Стоит отметить лишь тот факт, что на русскоязычном сайте нет совершенно никакого смысла устанавливать кодировку windows-1251 , исчерпывающе описанную в замечательной статье Википедии. Даже если все тексты на нем будут написаны исключительно на русском и не будет никаких вкраплений нестандартных символов. Вместо этого нужно просто выбрать универсальную кодировку UTF-8 , приняв это как данное, не забивая голову лишней информацией.
Дело в том, что нет смысла выбирать для своего сайта кодировку, которая поддерживает одни только символы славянских языков, таких как русский, украинский, белорусский, сербский, македонский и болгарский. Зачем изначально ограничивать себя и обрекать на возможные проблемы в дальнейшем. Что вы будете делать, если понадобится вставить символ, которого нет в поддерживаемых?
UTF-8 (от англ. Unicode Transformation Format) - восьмибитный формат преобразования Юникода, который получил всемирное признание и был стандартизирован как раз для избежания проблем, связанных с появлением кракозябров и неразберихой с нечитабельными текстами. Из чего можно смело сделать вывод, что в данном случае из двух зол нужно выбирать бóльшую и спать спокойно, не вникая в подробности, потому что тут и так все понятно. Посмотрите на размер Юпитера и Венеры для сравнения.
Основные способы установки правильной кодировки
Довольно часто проблемы с кодировкой сайта возникают не потому что не было выполнено ни одного из условий, о которых мы вам сейчас расскажем, а достаточно не выполнить всего лишь одно из них, чтобы текст на вашем сайте начал отображаться некорректно. После того, как вы установите кодировку всеми перечисленными способами, задача будет решена с вероятностью 99.9%. К такому заключению мы пришли на основании многолетнего опыта работы с сайтами на всевозможных хостинг-площадках, с использованием самых разных систем администрирования и настроек серверов.
Кодировка в.htaccess - AddDefaultCharset
Прежде всего, вам нужно установить кодировку всех страниц сайта по умолчанию с помощью одной очень полезной директивы htaccess - AddDefaultCharset, которая в дословном переводе с английского языка означает «ДобавитьКодировкуПоУмолчанию». Делается это очень просто:
AddDefaultCharset UTF-8
 Если вы не знаете что такое , то просто создайте текстовый файл в блокноте, а затем с помощью Total Commander-а переименуйте его в файл без названия, имеющий расширение HTACCESS ( - именно так и должно выглядеть полное имя вашего файла). После этого закачайте только что созданный файл в корневую директорию вашего сайта (в то же место, где находится главный исполняющий файл, например index.php
). И не забудьте вставить строку с кодировкой по умолчанию, которую мы только что приводили.
Если вы не знаете что такое , то просто создайте текстовый файл в блокноте, а затем с помощью Total Commander-а переименуйте его в файл без названия, имеющий расширение HTACCESS ( - именно так и должно выглядеть полное имя вашего файла). После этого закачайте только что созданный файл в корневую директорию вашего сайта (в то же место, где находится главный исполняющий файл, например index.php
). И не забудьте вставить строку с кодировкой по умолчанию, которую мы только что приводили.
Кодировка с помощью meta charset
 Метатеги способны отсылать браузеру информацию о странице в виде специальных заголовков, одним из которых как раз является тот, что нам нужен - charset
. Вообще метатеги могут иметь аж 4 различных атрибута:
Метатеги способны отсылать браузеру информацию о странице в виде специальных заголовков, одним из которых как раз является тот, что нам нужен - charset
. Вообще метатеги могут иметь аж 4 различных атрибута:
- content;
- http-equiv;
- name;
- scheme.
На самом деле, из представленных четырех атрибутов только один является обязательным - content , но существуют и исключения. Например в нашем случае будет использоваться сокращенная версия записи и мы установим кодировку с помощью метатега именно так:
Старый же формат записи давно канул в Лету и использовать его больше смысла нет:
Как известно, метатеги принято размещать внутри контейнера head . Об этом, наверное, знают уже все без исключения. Проделайте эту операцию и мы перейдем к следующему пункту в нашем списке.
Кодировка файла с помощью функции header PHP
Данный способ подойдет лишь тем, у кого сайт реализован с помощью самого популярного на данный момент языка программирования, по большей части ориентированного на создание веб-сайтов - PHP (Hyper Text Preprocessor). Для решения задачи, поставленной в рамках данной статьи, мы воспользуемся замечательной встроенной функцией header() , предназначенной для передачи заголовков, аналогично метатегам, но с тем небольшим отличием, что действие производится из PHP-скрипта, а не посредством вывода HTML-кода.
Установить кодировку UTF-8 для файла при помощи функции header() довольно просто - нужно просто вставить приведенный код в самое начало страницы, но разумеется внутри области действия PHP, которая обозначается так: или же так - .
Header("Content-type: text/html; charset=utf-8");
 Самым важным моментом здесь является то, что заголовки мы имеем право передавать только в том случае, если перед этим не было никакого вывода со стороны скрипта. Именно поэтому мы вставляем данный код в самое начало страницы. Делать это нужно с умом и хорошо понимать, что происходит, ведь вы можете быть уверены, что вставляете заголовок в начало файла, но можете не знать, что этот файл используется в другом файле, в который подтягивается с помощью функции require
или include
уже после того, как определенная информация была выведена на экран. Поэтому если вы не очень хорошо понимаете о чем сейчас идет речь, лучше перейдите к следующему шагу и вернитесь к этому, если 3 предыдущих не помогли установить правильную кодировку страниц вашего сайта.
Самым важным моментом здесь является то, что заголовки мы имеем право передавать только в том случае, если перед этим не было никакого вывода со стороны скрипта. Именно поэтому мы вставляем данный код в самое начало страницы. Делать это нужно с умом и хорошо понимать, что происходит, ведь вы можете быть уверены, что вставляете заголовок в начало файла, но можете не знать, что этот файл используется в другом файле, в который подтягивается с помощью функции require
или include
уже после того, как определенная информация была выведена на экран. Поэтому если вы не очень хорошо понимаете о чем сейчас идет речь, лучше перейдите к следующему шагу и вернитесь к этому, если 3 предыдущих не помогли установить правильную кодировку страниц вашего сайта.
Сохранение файлов в правильной кодировке
Одной из, наверное, самых распространенных причин возникновения кракозябров на сайте является некорректное кодирование самих фалов, использующихся для генерации конечного документа. Чаще всего такая проблема возникает у начинающих программистов, которые только делают свои первые шаги в освоении искусства . Когда в качестве движка сайта выбрана одна из популярных на данный момент систем администрирования, данная проблема может возникать в очень редких случаях, но если используется , то такое случается чуть ли не в каждом третьем случае.
 Как мы условились ранее, используемая нами кодировка на всех, даже на самых прожженных русскоязычных сайтах - UTF-8, поэтому и все файлы, составляющие движок сайта мы с вами будем кодировать в этом же формате. А для того, чтобы изменить кодировку самого файла, закачиваемого на сервер, обычного блокнота, предоставляемого операционной системой Windows будет конечно же не достаточно. Поэтому лучше воспользоваться сторонней программой, распространяемой бесплатно - Notepad++, которую можно скачать на официальном сайте без особых проблем.
Как мы условились ранее, используемая нами кодировка на всех, даже на самых прожженных русскоязычных сайтах - UTF-8, поэтому и все файлы, составляющие движок сайта мы с вами будем кодировать в этом же формате. А для того, чтобы изменить кодировку самого файла, закачиваемого на сервер, обычного блокнота, предоставляемого операционной системой Windows будет конечно же не достаточно. Поэтому лучше воспользоваться сторонней программой, распространяемой бесплатно - Notepad++, которую можно скачать на официальном сайте без особых проблем.
Успешно пройдя несложный процесс установки, вы должны будете назначить эту программу редактором по умолчанию, произвести некоторые настройки на свой вкус и поменять кодировку некорректно отображаемого файла так же, как показано на скриншоте. Т.е. вам необходимо выбрать значение «Кодировать в UTF-8 (без BOM)». Хорошим признаком того, что причина была именно в этом, будет то, что изначально не будет выбран ни один из вариантов и вам будет предложено «Преобразовать в UTF-8 (без BOM)». Если вы это увидели, то будьте уверены, что до решения проблемы с кодировкой остались считанные секунды.
 В дополнение хочется сказать лишь то, что выбирать нужно именно без BOM
. В противном случае, если кодировать просто в UTF-8 (с BOM), то в начале файла будут создаваться лишние байты. BOM - Byte Order Mark стараются не использовать именно в вебе при кодировании в формате UTF-8, т.к. это приводит к ошибкам из-за создания помех корректной PHP-интерпретации.
В дополнение хочется сказать лишь то, что выбирать нужно именно без BOM
. В противном случае, если кодировать просто в UTF-8 (с BOM), то в начале файла будут создаваться лишние байты. BOM - Byte Order Mark стараются не использовать именно в вебе при кодировании в формате UTF-8, т.к. это приводит к ошибкам из-за создания помех корректной PHP-интерпретации.
Ну а теперь, когда все необходимые действия выполнены, вы, скорей всего, на страницах вашего сайта увидите перед собой легко читаемый текст и вздохнете свободно 🙂