- Tutorial
О чем данный учебник
Данный учебник представляет собой что-то типа «штампа моей памяти» по языку SQL (DDL, DML), т.е. это информация, которая накопилась по ходу профессиональной деятельности и постоянно хранится в моей голове. Это для меня достаточный минимум, который применяется при работе с базами данных наиболее часто. Если встает необходимость применять более полные конструкции SQL, то я обычно обращаюсь за помощью в библиотеку MSDN расположенную в интернет. На мой взгляд, удержать все в голове очень сложно, да и нет особой необходимости в этом. Но знать основные конструкции очень полезно, т.к. они применимы практически в таком же виде во многих реляционных базах данных, таких как Oracle, MySQL, Firebird. Отличия в основном состоят в типах данных, которые могут отличаться в деталях. Основных конструкций языка SQL не так много, и при постоянной практике они быстро запоминаются. Например, для создания объектов (таблиц, ограничений, индексов и т.п.) достаточно иметь под рукой текстовый редактор среды (IDE) для работы с базой данных, и нет надобности изучать визуальный инструментарий заточенный для работы с конкретным типом баз данных (MS SQL, Oracle, MySQL, Firebird, …). Это удобно и тем, что весь текст находится перед глазами, и не нужно бегать по многочисленным вкладкам для того чтобы создать, например, индекс или ограничение. При постоянной работе с базой данных, создать, изменить, а особенно пересоздать объект при помощи скриптов получается в разы быстрее, чем если это делать в визуальном режиме. Так же в скриптовом режиме (соответственно, при должной аккуратности), проще задавать и контролировать правила наименования объектов (мое субъективное мнение). К тому же скрипты удобно использовать в случае, когда изменения, делаемые в одной базе данных (например, тестовой), необходимо перенести в таком же виде в другую базу (продуктивную).Язык SQL подразделяется на несколько частей, здесь я рассмотрю 2 наиболее важные его части:
- DML – Data Manipulation Language (язык манипулирования данными), который содержит следующие конструкции:
- SELECT – выборка данных
- INSERT – вставка новых данных
- UPDATE – обновление данных
- DELETE – удаление данных
- MERGE – слияние данных
Данный учебник создан по принципу Step by Step, т.е. необходимо читать его последовательно и желательно сразу же выполняя примеры. Но если по ходу у вас возникает потребность узнать о какой-то команде более детально, то используйте конкретный поиск в интернет, например, в библиотеке MSDN.
При написании данного учебника использовалась база данных MS SQL Server версии 2014, для выполнения скриптов я использовал MS SQL Server Management Studio (SSMS).
Кратко о MS SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) - утилита для Microsoft SQL Server для конфигурирования, управления и администрирования компонентов базы данных. Данная утилита содержит редактор скриптов (который в основном и будет нами использоваться) и графическую программу, которая работает с объектами и настройками сервера. Главным инструментом SQL Server Management Studio является Object Explorer, который позволяет пользователю просматривать, извлекать объекты сервера, а также управлять ими. Данный текст частично позаимствован с википедии.
Для создания нового редактора скрипта используйте кнопку «New Query/Новый запрос»:
Для смены текущей базы данных можно использовать выпадающий список:

Для выполнения определенной команды (или группы команд) выделите ее и нажмите кнопку «Execute/Выполнить» или же клавишу «F5». Если в редакторе в текущий момент находится только одна команда, или же вам необходимо выполнить все команды, то ничего выделять не нужно.

После выполнения скриптов, в особенности создающих объекты (таблицы, столбцы, индексы), чтобы увидеть изменения, используйте обновление из контекстного меню, выделив соответствующую группу (например, Таблицы), саму таблицу или группу Столбцы в ней.

Собственно, это все, что нам необходимо будет знать для выполнения приведенных здесь примеров. Остальное по утилите SSMS несложно изучить самостоятельно.
Немного теории
Реляционная база данных (РБД, или далее в контексте просто БД) представляет из себя совокупность таблиц, связанных между собой. Если говорить грубо, то БД – файл в котором данные хранятся в структурированном виде.СУБД – Система Управления этими Базами Данных, т.е. это комплекс инструментов для работы с конкретным типом БД (MS SQL, Oracle, MySQL, Firebird, …).
Примечание
Т.к. в жизни, в разговорной речи, мы по большей части говорим: «БД Oracle», или даже просто «Oracle», на самом деле подразумевая «СУБД Oracle», то в контексте данного учебника иногда будет употребляться термин БД. Из контекста, я думаю, будет понятно, о чем именно идет речь.
Таблица представляет из себя совокупность столбцов. Столбцы, так же могут называть полями или колонками, все эти слова будут использоваться как синонимы, выражающие одно и тоже.
Таблица – это главный объект РБД, все данные РБД хранятся построчно в столбцах таблицы. Строки, записи – тоже синонимы.
Для каждой таблицы, как и ее столбцов задаются наименования, по которым впоследствии к ним идет обращение.
Наименование объекта (имя таблицы, имя столбца, имя индекса и т.п.) в MS SQL может иметь максимальную длину 128 символов.
Для справки – в БД ORACLE наименования объектов могут иметь максимальную длину 30 символов. Поэтому для конкретной БД нужно вырабатывать свои правила для наименования объектов, чтобы уложиться в лимит по количеству символов.
SQL - язык позволяющий осуществлять запросы в БД посредством СУБД. В конкретной СУБД, язык SQL может иметь специфичную реализацию (свой диалект).
DDL и DML - подмножество языка SQL:
- Язык DDL служит для создания и модификации структуры БД, т.е. для создания/изменения/удаления таблиц и связей.
- Язык DML позволяет осуществлять манипуляции с данными таблиц, т.е. с ее строками. Он позволяет делать выборку данных из таблиц, добавлять новые данные в таблицы, а так же обновлять и удалять существующие данные.
В языке SQL можно использовать 2 вида комментариев (однострочный и многострочный):
Однострочный комментарий
и
/* многострочный комментарий */
Собственно, все для теории этого будет достаточно.
DDL – Data Definition Language (язык описания данных)
Для примера рассмотрим таблицу с данными о сотрудниках, в привычном для человека не являющимся программистом виде:В данном случае столбцы таблицы имеют следующие наименования: Табельный номер, ФИО, Дата рождения, E-mail, Должность, Отдел.
Каждый из этих столбцов можно охарактеризовать по типу содержащемся в нем данных:
- Табельный номер – целое число
- ФИО – строка
- Дата рождения – дата
- E-mail – строка
- Должность – строка
- Отдел – строка
Для начала будет достаточно запомнить только следующие основные типы данных используемые в MS SQL:
| Значение | Обозначение в MS SQL | Описание |
|---|---|---|
| Строка переменной длины | varchar(N) и nvarchar(N) |
При помощи числа N, мы можем указать максимально возможную длину строки для соответствующего столбца. Например, если мы хотим сказать, что значение столбца «ФИО» может содержать максимум 30 символов, то необходимо задать ей тип nvarchar(30). Отличие varchar от nvarchar заключается в том, что varchar позволяет хранить строки в формате ASCII, где один символ занимает 1 байт, а nvarchar хранит строки в формате Unicode, где каждый символ занимает 2 байта. Тип varchar стоит использовать только в том случае, если вы на 100% уверены, что в данном поле не потребуется хранить Unicode символы. Например, varchar можно использовать для хранения адресов электронной почты, т.к. они обычно содержат только ASCII символы. |
| Строка фиксированной длины | char(N) и nchar(N) |
От строки переменной длины данный тип отличается тем, что если длина строка меньше N символов, то она всегда дополняется справа до длины N пробелами и сохраняется в БД в таком виде, т.е. в базе данных она занимает ровно N символов (где один символ занимает 1 байт для char и 2 байта для типа nchar). На моей практике данный тип очень редко находит применение, а если и используется, то он используется в основном в формате char(1), т.е. когда поле определяется одним символом. |
| Целое число | int | Данный тип позволяет нам использовать в столбце только целые числа, как положительные, так и отрицательные. Для справки (сейчас это не так актуально для нас) – диапазон чисел который позволяет тип int от -2 147 483 648 до 2 147 483 647. Обычно это основной тип, который используется для задания идентификаторов. |
| Вещественное или действительное число | float | Если говорить простым языком, то это числа, в которых может присутствовать десятичная точка (запятая). |
| Дата | date | Если в столбце необходимо хранить только Дату, которая состоит из трех составляющих: Числа, Месяца и Года. Например, 15.02.2014 (15 февраля 2014 года). Данный тип можно использовать для столбца «Дата приема», «Дата рождения» и т.п., т.е. в тех случаях, когда нам важно зафиксировать только дату, или, когда составляющая времени нам не важна и ее можно отбросить или если она не известна. |
| Время | time | Данный тип можно использовать, если в столбце необходимо хранить только данные о времени, т.е. Часы, Минуты, Секунды и Миллисекунды. Например, 17:38:31.3231603 Например, ежедневное «Время отправления рейса». |
| Дата и время | datetime | Данный тип позволяет одновременно сохранить и Дату, и Время. Например, 15.02.2014 17:38:31.323 Для примера это может быть дата и время какого-нибудь события. |
| Флаг | bit | Данный тип удобно применять для хранения значений вида «Да»/«Нет», где «Да» будет сохраняться как 1, а «Нет» будет сохраняться как 0. |
Так же значение поля, в том случае если это не запрещено, может быть не указано, для этой цели используется ключевое слово NULL.
Для выполнения примеров создадим тестовую базу под названием Test.
Простую базу данных (без указания дополнительных параметров) можно создать, выполнив следующую команду:
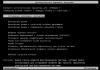
CREATE DATABASE Test
Удалить базу данных можно командой (стоит быть очень осторожным с данной командой):
DROP DATABASE Test
Для того, чтобы переключиться на нашу базу данных, можно выполнить команду:
USE Test
Или же выберите базу данных Test в выпадающем списке в области меню SSMS. При работе мною чаще используется именно этот способ переключения между базами.
Теперь в нашей БД мы можем создать таблицу используя описания в том виде как они есть, используя пробелы и символы кириллицы:
CREATE TABLE [Сотрудники]([Табельный номер] int,
[ФИО] nvarchar(30),
[Дата рождения] date,
nvarchar(30),
[Должность] nvarchar(30),
[Отдел] nvarchar(30))
В данном случае нам придется заключать имена в квадратные скобки […].
Но в базе данных для большего удобства все наименования объектов лучше задавать на латинице и не использовать в именах пробелы. В MS SQL обычно в данном случае каждое слово начинается с прописной буквы, например, для поля «Табельный номер», мы могли бы задать имя PersonnelNumber. Так же в имени можно использовать цифры, например, PhoneNumber1.
На заметку
В некоторых СУБД более предпочтительным может быть следующий формат наименований «PHONE_NUMBER», например, такой формат часто используется в БД ORACLE. Естественно при задании имя поля желательно чтобы оно не совпадало с ключевыми словами используемые в СУБД.
По этой причине можете забыть о синтаксисе с квадратными скобками и удалить таблицу [Сотрудники]:
DROP TABLE [Сотрудники]
Например, таблицу с сотрудниками можно назвать «Employees», а ее полям можно задать следующие наименования:
- ID – Табельный номер (Идентификатор сотрудника)
- Name – ФИО
- Birthday – Дата рождения
- Email – E-mail
- Position – Должность
- Department – Отдел
Теперь создадим нашу таблицу:
CREATE TABLE Employees(ID int,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30))
Для того, чтобы задать обязательные для заполнения столбцы, можно использовать опцию NOT NULL.
Для уже существующей таблицы поля можно переопределить при помощи следующих команд:
Обновление поля ID ALTER TABLE Employees ALTER COLUMN ID int NOT NULL -- обновление поля Name ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NOT NULL
На заметку
Общая концепция языка SQL для большинства СУБД остается одинаковой (по крайней мере, об этом я могу судить по тем СУБД, с которыми мне довелось поработать). Отличие DDL в разных СУБД в основном заключаются в типах данных (здесь могут отличаться не только их наименования, но и детали их реализации), так же может немного отличаться и сама специфика реализации языка SQL (т.е. суть команд одна и та же, но могут быть небольшие различия в диалекте, увы, но одного стандарта нет). Владея основами SQL вы легко сможете перейти с одной СУБД на другую, т.к. вам в данном случае нужно будет только разобраться в деталях реализации команд в новой СУБД, т.е. в большинстве случаев достаточно будет просто провести аналогию.Создание таблицы CREATE TABLE Employees(ID int, -- в ORACLE тип int - это эквивалент(обертка) для number(38) Name nvarchar2(30), -- nvarchar2 в ORACLE эквивалентен nvarchar в MS SQL Birthday date, Email nvarchar2(30), Position nvarchar2(30), Department nvarchar2(30)); -- обновление полей ID и Name (здесь вместо ALTER COLUMN используется MODIFY(…)) ALTER TABLE Employees MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL); -- добавление PK (в данном случае конструкция выглядит как и в MS SQL, она будет показана ниже) ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID);
Для ORACLE есть отличия в плане реализации типа varchar2, его кодировка зависит настроек БД и текст может сохраняться, например, в кодировке UTF-8. Помимо этого длину поля в ORACLE можно задать как в байтах, так и в символах, для этого используются дополнительные опции BYTE и CHAR, которые указываются после длины поля, например:NAME varchar2(30 BYTE) -- вместимость поля будет равна 30 байтам NAME varchar2(30 CHAR) -- вместимость поля будет равна 30 символов
Какая опция будет использоваться по умолчанию BYTE или CHAR, в случае простого указания в ORACLE типа varchar2(30), зависит от настроек БД, так же она иногда может задаваться в настройках IDE. В общем порой можно легко запутаться, поэтому в случае ORACLE, если используется тип varchar2 (а это здесь порой оправдано, например, при использовании кодировки UTF-8) я предпочитаю явно прописывать CHAR (т.к. обычно длину строки удобнее считать именно в символах).
Но в данном случае если в таблице уже есть какие-нибудь данные, то для успешного выполнения команд необходимо, чтобы во всех строках таблицы поля ID и Name были обязательно заполнены. Продемонстрируем это на примере, вставим в таблицу данные в поля ID, Position и Department, это можно сделать следующим скриптом:
INSERT Employees(ID,Position,Department) VALUES
(1000,N"Директор",N"Администрация"),
(1001,N"Программист",N"ИТ"),
(1002,N"Бухгалтер",N"Бухгалтерия"),
(1003,N"Старший программист",N"ИТ")
В данном случае, команда INSERT также выдаст ошибку, т.к. при вставке мы не указали значения обязательного поля Name.
В случае, если бы у нас в первоначальной таблице уже имелись эти данные, то команда «ALTER TABLE Employees ALTER COLUMN ID int NOT NULL» выполнилась бы успешно, а команда «ALTER TABLE Employees ALTER COLUMN Name int NOT NULL» выдала сообщение об ошибке, что в поле Name имеются NULL (не указанные) значения.
Добавим значения для полю Name и снова зальем данные:
Так же опцию NOT NULL можно использовать непосредственно при создании новой таблицы, т.е. в контексте команды CREATE TABLE.
Сначала удалим таблицу при помощи команды:
DROP TABLE Employees
Теперь создадим таблицу с обязательными для заполнения столбцами ID и Name:
CREATE TABLE Employees(ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30))
Можно также после имени столбца написать NULL, что будет означать, что в нем будут допустимы NULL-значения (не указанные), но этого делать не обязательно, так как данная характеристика подразумевается по умолчанию.
Если требуется наоборот сделать существующий столбец необязательным для заполнения, то используем следующий синтаксис команды:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NULL
Или просто:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30)
Так же данной командой мы можем изменить тип поля на другой совместимый тип, или же изменить его длину. Для примера давайте расширим поле Name до 50 символов:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(50)
Первичный ключ
При создании таблицы желательно, чтобы она имела уникальный столбец или же совокупность столбцов, которая уникальна для каждой ее строки – по данному уникальному значению можно однозначно идентифицировать запись. Такое значение называется первичным ключом таблицы. Для нашей таблицы Employees таким уникальным значением может быть столбец ID (который содержит «Табельный номер сотрудника» - пускай в нашем случае данное значение уникально для каждого сотрудника и не может повторяться).Создать первичный ключ к уже существующей таблице можно при помощи команды:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID)
Где «PK_Employees» это имя ограничения, отвечающего за первичный ключ. Обычно для наименования первичного ключа используется префикс «PK_» после которого идет имя таблицы.
Если первичный ключ состоит из нескольких полей, то эти поля необходимо перечислить в скобках через запятую:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения PRIMARY KEY(поле1,поле2,…)
Стоит отметить, что в MS SQL все поля, которые входят в первичный ключ, должны иметь характеристику NOT NULL.
Так же первичный ключ можно определить непосредственно при создании таблицы, т.е. в контексте команды CREATE TABLE. Удалим таблицу:
DROP TABLE Employees
А затем создадим ее, используя следующий синтаксис:
CREATE TABLE Employees(ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30),
CONSTRAINT PK_Employees PRIMARY KEY(ID) -- описываем PK после всех полей, как ограничение)
После создания зальем в таблицу данные:
INSERT Employees(ID,Position,Department,Name) VALUES
(1000,N"Директор",N"Администрация",N"Иванов И.И."),
(1001,N"Программист",N"ИТ",N"Петров П.П."),
(1002,N"Бухгалтер",N"Бухгалтерия",N"Сидоров С.С."),
(1003,N"Старший программист",N"ИТ",N"Андреев А.А.")
Если первичный ключ в таблице состоит только из значений одного столбца, то можно использовать следующий синтаксис:
CREATE TABLE Employees(ID int NOT NULL CONSTRAINT PK_Employees PRIMARY KEY, -- указываем как характеристику поля
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30))
На самом деле имя ограничения можно и не задавать, в этом случае ему будет присвоено системное имя (наподобие «PK__Employee__3214EC278DA42077»):
CREATE TABLE Employees(ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30),
PRIMARY KEY(ID))
Или:
CREATE TABLE Employees(ID int NOT NULL PRIMARY KEY,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30))
Но я бы рекомендовал для постоянных таблиц всегда явно задавать имя ограничения, т.к. по явно заданному и понятному имени с ним впоследствии будет легче проводить манипуляции, например, можно произвести его удаление:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
Но такой краткий синтаксис, без указания имен ограничений, удобно применять при создании временных таблиц БД (имя временной таблицы начинается с # или ##), которые после использования будут удалены.
Подытожим
На данный момент мы рассмотрели следующие команды:- CREATE TABLE имя_таблицы (перечисление полей и их типов, ограничений) – служит для создания новой таблицы в текущей БД;
- DROP TABLE имя_таблицы – служит для удаления таблицы из текущей БД;
- ALTER TABLE имя_таблицы ALTER COLUMN имя_столбца … – служит для обновления типа столбца или для изменения его настроек (например для задания характеристики NULL или NOT NULL);
- ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения PRIMARY KEY (поле1, поле2,…) – добавление первичного ключа к уже существующей таблице;
- ALTER TABLE имя_таблицы DROP CONSTRAINT имя_ограничения – удаление ограничения из таблицы.
Немного про временные таблицы
Вырезка из MSDN. В MS SQL Server существует два вида временных таблиц: локальные (#) и глобальные (##). Локальные временные таблицы видны только их создателям до завершения сеанса соединения с экземпляром SQL Server, как только они впервые созданы. Локальные временные таблицы автоматически удаляются после отключения пользователя от экземпляра SQL Server. Глобальные временные таблицы видны всем пользователям в течение любых сеансов соединения после создания этих таблиц и удаляются, когда все пользователи, ссылающиеся на эти таблицы, отключаются от экземпляра SQL Server.
Временные таблицы создаются в системной базе tempdb, т.е. создавая их мы не засоряем основную базу, в остальном же временные таблицы полностью идентичны обычным таблицам, их так же можно удалить при помощи команды DROP TABLE. Чаще используются локальные (#) временные таблицы.
Для создания временной таблицы можно использовать команду CREATE TABLE:
CREATE TABLE #Temp(ID int,
Name nvarchar(30))
Так как временная таблица в MS SQL аналогична обычной таблице, ее соответственно так же можно удалить самому командой DROP TABLE:
DROP TABLE #Temp
Так же временную таблицу (как собственно и обычную таблицу) можно создать и сразу заполнить данными возвращаемые запросом используя синтаксис SELECT … INTO:
SELECT ID,Name
INTO #Temp
FROM Employees
На заметку
В разных СУБД реализация временных таблиц может отличаться. Например, в СУБД ORACLE и Firebird структура временных таблиц должна быть определена заранее командой CREATE GLOBAL TEMPORARY TABLE с указанием специфики хранения в ней данных, дальше уже пользователь видит ее среди основных таблиц и работает с ней как с обычной таблицей.
Нормализация БД – дробление на подтаблицы (справочники) и определение связей
Наша текущая таблица Employees имеет недостаток в том, что в полях Position и Department пользователь может ввести любой текст, что в первую очередь чревато ошибками, так как он у одного сотрудника может указать в качестве отдела просто «ИТ», а у второго сотрудника, например, ввести «ИТ-отдел», у третьего «IT». В итоге будет непонятно, что имел ввиду пользователь, т.е. являются ли данные сотрудники работниками одного отдела, или же пользователь описался и это 3 разных отдела? А тем более, в этом случае, мы не сможем правильно сгруппировать данные для какого-то отчета, где, может требоваться показать количество сотрудников в разрезе каждого отдела.Второй недостаток заключается в объеме хранения данной информации и ее дублированием, т.е. для каждого сотрудника указывается полное наименование отдела, что требует в БД места для хранения каждого символа из названия отдела.
Третий недостаток – сложность обновления данных полей, в случае если изменится название какой-то должности, например, если потребуется переименовать должность «Программист», на «Младший программист». В данном случае нам придется вносить изменения в каждую строчку таблицы, у которой Должность равняется «Программист».
Чтобы избежать данных недостатков и применяется, так называемая, нормализация базы данных – дробление ее на подтаблицы, таблицы справочники. Не обязательно лезть в дебри теории и изучать что из себя представляют нормальные формы, достаточно понимать суть нормализации.
Давайте создадим 2 таблицы справочники «Должности» и «Отделы», первую назовем Positions, а вторую соответственно Departments:
CREATE TABLE Positions(ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY,
Name nvarchar(30) NOT NULL)
CREATE TABLE Departments(ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY,
Name nvarchar(30) NOT NULL)
Заметим, что здесь мы использовали новую опцию IDENTITY, которая говорит о том, что данные в столбце ID будут нумероваться автоматически, начиная с 1, с шагом 1, т.е. при добавлении новых записей им последовательно будут присваиваться значения 1, 2, 3, и т.д. Такие поля обычно называют автоинкрементными. В таблице может быть определено только одно поле со свойством IDENTITY и обычно, но необязательно, такое поле является первичным ключом для данной таблицы.
На заметку
В разных СУБД реализация полей со счетчиком может делаться по своему. В MySQL, например, такое поле определяется при помощи опции AUTO_INCREMENT. В ORACLE и Firebird раньше данную функциональность можно было съэмулировать при помощи использования последовательностей (SEQUENCE). Но насколько я знаю в ORACLE сейчас добавили опцию GENERATED AS IDENTITY.
Давайте заполним эти таблицы автоматически, на основании текущих данных записанных в полях Position и Department таблицы Employees:
Заполняем поле Name таблицы Positions, уникальными значениями из поля Position таблицы Employees
INSERT Positions(Name)
SELECT DISTINCT Position
FROM Employees
WHERE Position IS NOT NULL -- отбрасываем записи у которых позиция не указана
То же самое проделаем для таблицы Departments:
INSERT Departments(Name)
SELECT DISTINCT Department
FROM Employees
WHERE Department IS NOT NULL
Если теперь мы откроем таблицы Positions и Departments, то увидим пронумерованный набор значений по полю ID:
SELECT * FROM Positions
SELECT * FROM Departments
Данные таблицы теперь и будут играть роль справочников для задания должностей и отделов. Теперь мы будем ссылаться на идентификаторы должностей и отделов. В первую очередь создадим новые поля в таблице Employees для хранения данных идентификаторов:
Добавляем поле для ID должности
ALTER TABLE Employees ADD PositionID int
-- добавляем поле для ID отдела
ALTER TABLE Employees ADD DepartmentID int
Тип ссылочных полей должен быть каким же, как и в справочниках, в данном случае это int.
Так же добавить в таблицу сразу несколько полей можно одной командой, перечислив поля через запятую:
ALTER TABLE Employees ADD PositionID int, DepartmentID int
Теперь пропишем ссылки (ссылочные ограничения - FOREIGN KEY) для этих полей, для того чтобы пользователь не имел возможности записать в данные поля, значения, отсутствующие среди значений ID находящихся в справочниках.
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_PositionID
FOREIGN KEY(PositionID) REFERENCES Positions(ID)
И то же самое сделаем для второго поля:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_DepartmentID
FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
Теперь пользователь в данные поля сможет занести только значения ID из соответствующего справочника. Соответственно, чтобы использовать новый отдел или должность, он первым делом должен будет добавить новую запись в соответствующий справочник. Т.к. должности и отделы теперь хранятся в справочниках в одном единственном экземпляре, то чтобы изменить название, достаточно изменить его только в справочнике.
Имя ссылочного ограничения, обычно является составным, оно состоит из префикса «FK_», затем идет имя таблицы и после знака подчеркивания идет имя поля, которое ссылается на идентификатор таблицы-справочника.
Идентификатор (ID) обычно является внутренним значением, которое используется только для связей и какое значение там хранится, в большинстве случаев абсолютно безразлично, поэтому не нужно пытаться избавиться от дырок в последовательности чисел, которые возникают по ходу работы с таблицей, например, после удаления записей из справочника.
ALTER TABLE таблица ADD CONSTRAINT имя_ограничения
FOREIGN KEY(поле1,поле2,…) REFERENCES таблица_справочник(поле1,поле2,…)
В данном случае в таблице «таблица_справочник» первичный ключ представлен комбинацией из нескольких полей (поле1, поле2,…).
Собственно, теперь обновим поля PositionID и DepartmentID значениями ID из справочников. Воспользуемся для этой цели DML командой UPDATE:
UPDATE e
SET
PositionID=(SELECT ID FROM Positions WHERE Name=e.Position),
DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department)
FROM Employees e
Посмотрим, что получилось, выполнив запрос:
SELECT * FROM Employees
Всё, поля PositionID и DepartmentID заполнены соответствующие должностям и отделам идентификаторами надобности в полях Position и Department в таблице Employees теперь нет, можно удалить эти поля:
ALTER TABLE Employees DROP COLUMN Position,Department
Теперь таблица у нас приобрела следующий вид:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | NULL | NULL | 2 | 1 |
| 1001 | Петров П.П. | NULL | NULL | 3 | 3 |
| 1002 | Сидоров С.С. | NULL | NULL | 1 | 2 |
| 1003 | Андреев А.А. | NULL | NULL | 4 | 3 |
Т.е. мы в итоге избавились от хранения избыточной информации. Теперь, по номерам должности и отдела можем однозначно определить их названия, используя значения в таблицах-справочниках:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName
FROM Employees e
LEFT JOIN Departments d ON d.ID=e.DepartmentID
LEFT JOIN Positions p ON p.ID=e.PositionID
В инспекторе объектов мы можем увидеть все объекты, созданные для в данной таблицы. Отсюда же можно производить разные манипуляции с данными объектами – например, переименовывать или удалять объекты.

Так же стоит отметить, что таблица может ссылаться сама на себя, т.е. можно создать рекурсивную ссылку. Для примера добавим в нашу таблицу с сотрудниками еще одно поле ManagerID, которое будет указывать на сотрудника, которому подчиняется данный сотрудник. Создадим поле:
ALTER TABLE Employees ADD ManagerID int
В данном поле допустимо значение NULL, поле будет пустым, если, например, над сотрудником нет вышестоящих.
Теперь создадим FOREIGN KEY на таблицу Employees:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID
FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
Давайте, теперь создадим диаграмму и посмотрим, как выглядят на ней связи между нашими таблицами:


В результате мы должны увидеть следующую картину (таблица Employees связана с таблицами Positions и Depertments, а так же ссылается сама на себя):

Напоследок стоит сказать, что ссылочные ключи могут включать дополнительные опции ON DELETE CASCADE и ON UPDATE CASCADE, которые говорят о том, как вести себя при удалении или обновлении записи, на которую есть ссылки в таблице-справочнике. Если эти опции не указаны, то мы не можем изменить ID в таблице справочнике у той записи, на которую есть ссылки из другой таблицы, так же мы не сможем удалить такую запись из справочника, пока не удалим все строки, ссылающиеся на эту запись или, же обновим в этих строках ссылки на другое значение.
Для примера пересоздадим таблицу с указанием опции ON DELETE CASCADE для FK_Employees_DepartmentID:
DROP TABLE Employees
CREATE TABLE Employees(ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
ManagerID int,
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
ON DELETE CASCADE,
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID))
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES
(1000,N"Иванов И.И.","19550219",2,1,NULL),
(1001,N"Петров П.П.","19831203",3,3,1003),
(1002,N"Сидоров С.С.","19760607",1,2,1000),
(1003,N"Андреев А.А.","19820417",4,3,1000)
Удалим отдел с идентификатором 3 из таблицы Departments:
DELETE Departments WHERE ID=3
Посмотрим на данные таблицы Employees:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | |
|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Сидоров С.С. | 1976-06-07 | NULL | 1 | 2 | 1000 |
Как видим, данные по отделу 3 из таблицы Employees так же удалились.
Опция ON UPDATE CASCADE ведет себя аналогично, но действует она при обновлении значения ID в справочнике. Например, если мы поменяем ID должности в справочнике должностей, то в этом случае будет производиться обновление DepartmentID в таблице Employees на новое значение ID которое мы задали в справочнике. Но в данном случае это продемонстрировать просто не получится, т.к. у колонки ID в таблице Departments стоит опция IDENTITY, которая не позволит нам выполнить следующий запрос (сменить идентификатор отдела 3 на 30):
UPDATE Departments
SET
ID=30
WHERE ID=3
Главное понять суть этих 2-х опций ON DELETE CASCADE и ON UPDATE CASCADE. Я применяю эти опции очень в редких случаях и рекомендую хорошо подумать, прежде чем указывать их в ссылочном ограничении, т.к. при нечаянном удалении записи из таблицы справочника это может привести к большим проблемам и создать цепную реакцию.
Восстановим отдел 3:
Даем разрешение на добавление/изменение IDENTITY значения
SET IDENTITY_INSERT Departments ON
INSERT Departments(ID,Name) VALUES(3,N"ИТ")
-- запрещаем добавление/изменение IDENTITY значения
SET IDENTITY_INSERT Departments OFF
Полностью очистим таблицу Employees при помощи команды TRUNCATE TABLE:
TRUNCATE TABLE Employees
И снова перезальем в нее данные используя предыдущую команду INSERT:
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N"Иванов И.И.","19550219",2,1,NULL), (1001,N"Петров П.П.","19831203",3,3,1003), (1002,N"Сидоров С.С.","19760607",1,2,1000), (1003,N"Андреев А.А.","19820417",4,3,1000)
Подытожим
На данным момент к нашим знаниям добавилось еще несколько команд DDL:- Добавление свойства IDENTITY к полю – позволяет сделать это поле автоматически заполняемым (полем-счетчиком) для таблицы;
- ALTER TABLE имя_таблицы ADD перечень_полей_с_характеристиками – позволяет добавить новые поля в таблицу;
- ALTER TABLE имя_таблицы DROP COLUMN перечень_полей – позволяет удалить поля из таблицы;
- ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения FOREIGN KEY (поля) REFERENCES таблица_справочник(поля) – позволяет определить связь между таблицей и таблицей справочником.
Прочие ограничения – UNIQUE, DEFAULT, CHECK
При помощи ограничения UNIQUE можно сказать что значения для каждой строки в данном поле или в наборе полей должно быть уникальным. В случае таблицы Employees, такое ограничение мы можем наложить на поле Email. Только предварительно заполним Email значениями, если они еще не определены:UPDATE Employees SET Email="[email protected]" WHERE ID=1000
UPDATE Employees SET Email="[email protected]" WHERE ID=1001
UPDATE Employees SET Email="[email protected]" WHERE ID=1002
UPDATE Employees SET Email="[email protected]" WHERE ID=1003
А теперь можно наложить на это поле ограничение-уникальности:
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
Теперь пользователь не сможет внести один и тот же E-Mail у нескольких сотрудников.
Ограничение уникальности обычно именуется следующим образом – сначала идет префикс «UQ_», далее название таблицы и после знака подчеркивания идет имя поля, на которое накладывается данное ограничение.
Соответственно если уникальной в разрезе строк таблицы должна быть комбинация полей, то перечисляем их через запятую:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения UNIQUE(поле1,поле2,…)
При помощи добавления к полю ограничения DEFAULT мы можем задать значение по умолчанию, которое будет подставляться в случае, если при вставке новой записи данное поле не будет перечислено в списке полей команды INSERT. Данное ограничение можно задать непосредственно при создании таблицы.
Давайте добавим в таблицу Employees новое поле «Дата приема» и назовем его HireDate и скажем что значение по умолчанию у данного поля будет текущая дата:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
Или если столбец HireDate уже существует, то можно использовать следующий синтаксис:
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
Здесь я не указал имя ограничения, т.к. в случае DEFAULT у меня сложилось мнение, что это не столь критично. Но если делать по-хорошему, то, думаю, не нужно лениться и стоит задать нормальное имя. Делается это следующим образом:
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
Та как данного столбца раньше не было, то при его добавлении в каждую запись в поле HireDate будет вставлено текущее значение даты.
При добавлении новой записи, текущая дата так же будет вставлена автоматом, конечно если мы ее явно не зададим, т.е. не укажем в списке столбцов. Покажем это на примере, не указав поле HireDate в перечне добавляемых значений:
INSERT Employees(ID,Name,Email)VALUES(1004,N"Сергеев С.С.","[email protected]")
Посмотрим, что получилось:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | HireDate | |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 1955-02-19 | [email protected] | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Петров П.П. | 1983-12-03 | [email protected] | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Сидоров С.С. | 1976-06-07 | [email protected] | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Андреев А.А. | 1982-04-17 | [email protected] | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Сергеев С.С. | NULL | [email protected] | NULL | NULL | NULL | 2015-04-08 |
Проверочное ограничение CHECK используется в том случае, когда необходимо осуществить проверку вставляемых в поле значений. Например, наложим данное ограничение на поле табельный номер, которое у нас является идентификатором сотрудника (ID). При помощи данного ограничения скажем, что табельные номера должны иметь значение от 1000 до 1999:
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
Ограничение обычно именуется так же, сначала идет префикс «CK_», затем имя таблицы и имя поля, на которое наложено это ограничение.
Попробуем вставить недопустимую запись для проверки, что ограничение работает (мы должны получить соответствующую ошибку):
INSERT Employees(ID,Email) VALUES(2000,"[email protected]")
А теперь изменим вставляемое значение на 1500 и убедимся, что запись вставится:
INSERT Employees(ID,Email) VALUES(1500,"[email protected]")
Можно так же создать ограничения UNIQUE и CHECK без указания имени:
ALTER TABLE Employees ADD UNIQUE(Email)
ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
Но это не очень хорошая практика и лучше задавать имя ограничения в явном виде, т.к. чтобы разобраться потом, что будет сложнее, нужно будет открывать объект и смотреть, за что он отвечает.

При хорошем наименовании много информации об ограничении можно узнать непосредственно по его имени.
И, соответственно, все эти ограничения можно создать сразу же при создании таблицы, если ее еще нет. Удалим таблицу:
DROP TABLE Employees
И пересоздадим ее со всеми созданными ограничениями одной командой CREATE TABLE:
CREATE TABLE Employees(ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
HireDate date NOT NULL DEFAULT SYSDATETIME(), -- для DEFAULT я сделаю исключение
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID),
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT UQ_Employees_Email UNIQUE (Email),
CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999))
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES (1000,N"Иванов И.И.","19550219","[email protected]",2,1), (1001,N"Петров П.П.","19831203","[email protected]",3,3), (1002,N"Сидоров С.С.","19760607","[email protected]",1,2), (1003,N"Андреев А.А.","19820417","[email protected]",4,3)
Немного про индексы, создаваемые при создании ограничений PRIMARY KEY и UNIQUE
Как можно увидеть на скриншоте выше, при создании ограничений PRIMARY KEY и UNIQUE автоматически создались индексы с такими же названиями (PK_Employees и UQ_Employees_Email). По умолчанию индекс для первичного ключа создается как CLUSTERED, а для всех остальных индексов как NONCLUSTERED. Стоит сказать, что понятие кластерного индекса есть не во всех СУБД. Таблица может иметь только один кластерный (CLUSTERED) индекс. CLUSTERED – означает, что записи таблицы будут сортироваться по этому индексу, так же можно сказать, что этот индекс имеет непосредственный доступ ко всем данным таблицы. Это так сказать главный индекс таблицы. Если сказать еще грубее, то это индекс, прикрученный к таблице. Кластерный индекс – это очень мощное средство, которое может помочь при оптимизации запросов, пока просто запомним это. Если мы хотим сказать, чтобы кластерный индекс использовался не в первичном ключе, а для другого индекса, то при создании первичного ключа мы должны указать опцию NONCLUSTERED:ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения
PRIMARY KEY NONCLUSTERED(поле1,поле2,…)
Для примера сделаем индекс ограничения PK_Employees некластерным, а индекс ограничения UQ_Employees_Email кластерным. Первым делом удалим данные ограничения:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
А теперь создадим их с опциями CLUSTERED и NONCLUSTERED:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID)
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
Теперь, выполнив выборку из таблицы Employees, мы увидим, что записи отсортировались по кластерному индексу UQ_Employees_Email:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | |
|---|---|---|---|---|---|---|
| 1003 | Андреев А.А. | 1982-04-17 | [email protected] | 4 | 3 | 2015-04-08 |
| 1000 | Иванов И.И. | 1955-02-19 | [email protected] | 2 | 1 | 2015-04-08 |
| 1001 | Петров П.П. | 1983-12-03 | [email protected] | 3 | 3 | 2015-04-08 |
| 1002 | Сидоров С.С. | 1976-06-07 | [email protected] | 1 | 2 | 2015-04-08 |
До этого, когда кластерным индексом был индекс PK_Employees, записи по умолчанию сортировались по полю ID.
Но в данном случае это всего лишь пример, который показывает суть кластерного индекса, т.к. скорее всего к таблице Employees будут делаться запросы по полю ID и в каких-то случаях, возможно, она сама будет выступать в роли справочника.
Для справочников обычно целесообразно, чтобы кластерный индекс был построен по первичному ключу, т.к. в запросах мы часто ссылаемся на идентификатор справочника для получения, например, наименования (Должности, Отдела). Здесь вспомним, о чем я писал выше, что кластерный индекс имеет прямой доступ к строкам таблицы, а отсюда следует, что мы можем получить значение любого столбца без дополнительных накладных расходов.
Кластерный индекс выгодно применять к полям, по которым выборка идет наиболее часто.
Иногда в таблицах создают ключ по суррогатному полю, вот в этом случае бывает полезно сохранить опцию CLUSTERED индекс для более подходящего индекса и указать опцию NONCLUSTERED при создании суррогатного первичного ключа.
Подытожим
На данном этапе мы познакомились со всеми видами ограничений, в их самом простом виде, которые создаются командой вида «ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения …»:- PRIMARY KEY – первичный ключ;
- FOREIGN KEY – настройка связей и контроль ссылочной целостности данных;
- UNIQUE – позволяет создать уникальность;
- CHECK – позволяет осуществлять корректность введенных данных;
- DEFAULT – позволяет задать значение по умолчанию;
- Так же стоит отметить, что все ограничения можно удалить, используя команду «ALTER TABLE имя_таблицы DROP CONSTRAINT имя_ограничения».
Создание самостоятельных индексов
Под самостоятельностью здесь имеются в виду индексы, которые создаются не для ограничения PRIMARY KEY или UNIQUE.Индексы по полю или полям можно создавать следующей командой:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Так же здесь можно указать опции CLUSTERED, NONCLUSTERED, UNIQUE, а так же можно указать направление сортировки каждого отдельного поля ASC (по умолчанию) или DESC:
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
При создании некластерного индекса опцию NONCLUSTERED можно отпустить, т.к. она подразумевается по умолчанию, здесь она показана просто, чтобы указать позицию опции CLUSTERED или NONCLUSTERED в команде.
Удалить индекс можно следующей командой:
DROP INDEX IDX_Employees_Name ON Employees
Простые индексы так же, как и ограничения, можно создать в контексте команды CREATE TABLE.
Для примера снова удалим таблицу:
DROP TABLE Employees
И пересоздадим ее со всеми созданными ограничениями и индексами одной командой CREATE TABLE:
CREATE TABLE Employees(ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(),
ManagerID int,
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID),
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID),
CONSTRAINT UQ_Employees_Email UNIQUE(Email),
CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999),
INDEX IDX_Employees_Name(Name))
Напоследок вставим в таблицу наших сотрудников:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES
(1000,N"Иванов И.И.","19550219","[email protected]",2,1,NULL),
(1001,N"Петров П.П.","19831203","[email protected]",3,3,1003),
(1002,N"Сидоров С.С.","19760607","[email protected]",1,2,1000),
(1003,N"Андреев А.А.","19820417","[email protected]",4,3,1000)
Дополнительно стоит отметить, что в некластерный индекс можно включать значения при помощи указания их в INCLUDE. Т.е. в данном случае INCLUDE-индекс чем-то будет напоминать кластерный индекс, только теперь не индекс прикручен к таблице, а необходимые значения прикручены к индексу. Соответственно, такие индексы могут очень повысить производительность запросов на выборку (SELECT), если все перечисленные поля имеются в индексе, то возможно обращений к таблице вообще не понадобится. Но это естественно повышает размер индекса, т.к. значения перечисленных полей дублируются в индексе.
Вырезка из MSDN. Общий синтаксис команды для создания индексовCREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON
Подытожим
Индексы могут повысить скорость выборки данных (SELECT), но индексы уменьшают скорость модификации данных таблицы, т.к. после каждой модификации системе будет необходимо перестроить все индексы для конкретной таблицы.Желательно в каждом случае найти оптимальное решение, золотую середину, чтобы и производительность выборки, так и модификации данных была на должном уровне. Стратегия по созданию индексов и их количества может зависеть от многих факторов, например, насколько часто изменяются данные в таблице.
Заключение по DDL
Как можно увидеть, язык DDL не так сложен, как может показаться на первый взгляд. Здесь я смог показать практически все его основные конструкции, оперируя всего тремя таблицами.Главное - понять суть, а остальное дело практики.
Удачи вам в освоении этого замечательного языка под названием SQL.
Мартин Грабер «SQL для простых смертных» Лори, 2014 год, 382 стр. (11,2 мб. pdf)
Книгу можно охарактеризовать, как руководство для начинающих. Structured Query Language — SQL, язык программирования для создания и управления реляционными базами данных (прикладная, логическая модель построения совокупности (баз) данных). Книга рассчитана на самый простой (низкий) уровень подготовки в IT-сфере, то есть достаточно знаний в объеме школьной программы. Но это не значит, что материал руководства является только введением в этот язык программирования — нет, SQL описан довольно глубоко (утверждение автора).
Каждая глава добавляет новые данные с описанием взаимосвязанных понятий и определений. Весь последующий материал базируются на предыдущем — рассмотренном ранее, с рассмотрением в конце главы практических вопросов для лучшего усваивания полученных знаний. Ответы вы найдете в приложении А.
Введение в SQL представлено в первых семи главах, которые обязательны к изучению — если вы используете руководство, как SQL для начинающих. В последующих семи (с 8 по 14) главах рассматриваются более сложные примеры: комбинированные запросы, запросы сразу к нескольким таблицам. Другие возможности SQL: создание и редактирование таблиц, ввод и установка значений, открытие и закрытие доступа к созданным таблицам - изложены в главах с 15 по 23. В заключении о структуре баз данных и о возможности использования SQL в программах, разработанных на других языках. В приложениях приводится руководство по командам SQL и ответы на задания. Книга идеально подойдет для начинающих изучать SQL.
ISBN: 978-5-85582-301-1
Глава 1. Введение в реляционные базы данных
1
Что такое реляционная база данных? 3
Пример базы данных 5
Итоги 7
Глава 2. Введение в SQL
9
Как работает SQL? 10
Различные типы данных 12
Итоги 15
Глава 3. Использование SQL для выборки данных из таблиц
17
Формирование запроса 18
Определение выборки - предложение WHERE 24
Итоги 26
Глава 4. Использование реляционных и булевых операторов для создания более сложных предикатов
29
Реляционные операторы 30
Булевы операторы 32
Итоги 37
Глава 5. Использование специальных операторов в «условиях»
39
Оператор IN 40
Оператор BETWEEN 41
Оператор LIKE 44
Оператор IS NULL 47
Итоги 49
Глава 6. Суммирование данных с помощью функции агрегирования
51
Что такое функции агрегирования? 52
Итоги 61
Глава 7. Форматирование результатов запросов
63
Строки и выражения 64
Упорядочение выходных полей 67
Итоги 71
Глава 8. Использование множества таблиц в одном запросе
75
Соединение таблиц 76
Итоги 81
Глава 9. Операция соединения, операнды которой представлены одной таблицей
83
Как выполняется операция соединения двух копий одной таблицы 84
Итоги 90
Глава 10. Вложение запросов
93
Как выполняются подзапросы? 94
Итоги 105
Глава 11. Связанные подзапросы
107
Как формировать связанные подзапросы 108
Итоги 115
Глава 12. Использование оператора EXISTS
117
Как работает оператор EXISTS? 118
Использование EXISTS со связанными подзапросами 119
Итоги 124
Глава 13. Использование операторов ANY, ALL и SOME
127
Специальный оператор ANY или SOME 128
Специальный оператор ALL 135
Функционирование ANY. ALL и EXISTS при потере данных или
с неизвестными данными 139
Итоги 143
Глава 14. Использование предложения UNION
145
Объединение множества запросов в один 146
Использование UNION с ORDER BY 151
Итоги 157
Глава 15. Ввод, удаление и изменение значений нолей
159
Команды обновления DML 160
Ввод значений 160
Исключение строк из таблицы 162
Изменение значений полей 163
Итоги 165
Глава 16. Использование подзапросов с командами обновления
167
Использование подзапросов в INSERT 168
Использование подзапросов с DELETE 170
Использование подзапросов с UPDATE 174
Итоги 177
Глава 17. Создание таблиц
178
Команда CREATE TABLE 179
Индексы 181
Изменение таблицы, которая уже была создана 182
Исключение таблицы 183
Итоги 185
Глава 18. Ограничения на множество допустимых значений данных
186
Ограничения в таблицах 195
Итоги 197
Глава 19. Поддержка целостности данных
198
Внешние и родительские ключи 199
Ограничения FOREIGN KEY (внешнего ключа) 204
Что происходит при выполнении команды обновления 209
Итоги 211
Глава 20. Введение в представления
212
Что такое представления? 212
Команда CREATE VIEW 221
Итоги 223
Глава 21. Изменение значений с помощью представлений
224
Обновление представлений 228
Выбор значений, размещенных в представлениях 232
Итоги 235
Глава 22. Определение прав доступа к данным
236
Пользователи 237
Передача привилегий 241
Лишение привилегий 245
Другие типы привилегий 247
Итоги 249
Глава 23. Глобальные аспекты SQL
250
Переименование таблиц 252
Каким образом база данных размещается для пользователя? 253
Когда изменения становятся постоянными? 255
Как SQL работает одновременно с множеством пользователей Итоги 259
Глава 24. Как поддерживается порядок в базе данных SQL
261
Системный каталог 262
Приветствую вас на моем блоге сайт. Сегодня поговорим про sql запросы для начинающих. У некоторых вебмастеров может возникнуть вопрос. Зачем изучать sql? Разве нельзя обойтись ?
Оказывается, что для создания профессионального интернет-проекта этого будет недостаточно. Sql используется чтобы работать с БД и создания приложений для Вордпресс. Рассмотрим, как использовать запросы подробнее.
Что это такое
Sql - язык структурированных запросов. Создан для определения типа данных, предоставления доступа к ним и обработке информации за короткие промежутки времени. Он описывает компоненты или какие-то результаты, которые вы хотите видеть на интернет-проекте.
Если говорить по-простому, то этот язык программирования позволяет добавлять, изменять, искать и отображать информацию в БД. Популярность mysql связана с тем, что он используется для создания динамических интернет-проектов, основа которых составляет база данных. Поэтому для разработки функционального блога вам необходимо выучить этот язык.

Что может делать
Язык sql позволяет:
- создавать таблицы;
- изменять получать и хранить разные данные;
- объединять информацию в блоки;
- защитить данные;
- создавать запросы в access.
Важно! Разобравшись с sql вы сможете писать приложения для Вордпресс любой сложности.
Какая структура
БД состоит из таблиц, которые можно представить в виде Эксель файла.
У нее имеется имя, колонки и ряд с какой-то информацией. Создавать подобные таблицы можно при помощи sql запросов.
Что нужно знать

Основные моменты при изучении Sql
Как уже отмечалось выше, запросы применяются для обработки и ввода новой информации в БД, состоящую из таблиц. Каждая ее строка - это отдельная запись. Итак, создадим БД. Для этого напишите команду:
Create database ‘bazaname’
В кавычках пишем имя БД на латинице. Старайтесь придумать для нее понятное имя. Не создавайте базу типа «111», «www» и тому подобное.
После создания БД устанавливаем :
SET NAMES ‘utf-8’
Это нужно чтобы контент на сайте правильно отображаться.
Теперь создаем таблицу:
CREATE TABLE ‘bazaname’ . ‘table’ (
id INT(8) NOT NULL AUTO_INCREMENT PRIMARY KEY,
log VARCHAR(10),
pass VARCHAR(10),
date DATE

Во второй строке мы прописали три атрибута. Посмотрим, что они означают:
- Атрибут NOT NULL означает, что ячейка не будет пустой (поле обязательное для заполнения);
- Значение AUTO_INCREMENT — автозаполнение;
- PRIMARY KEY — первичный ключ.
Как добавить информацию
Чтобы заполнить поля созданной таблицы значениями, используется оператор INSERT. Пишем такие строки кода:
INSERT INTO ‘table’
(login , pass , date) VALUES
(‘Vasa’, ‘87654321’, ‘2017-06-21 18:38:44’);
В скобках указываем название столбцов, а в следующей - значения.
Важно! Соблюдайте последовательность названий и значений столбцов.
Как обновить информацию
Для этого используется команда UPDATE. Посмотрим, как изменить пароль для конкретного пользователя. Пишем такие строки кода:
UPDATE ‘table’ SET pass = ‘12345678’ WHERE id = ‘1’
Теперь поменяйте пароль ‘12345678’. Изменения происходят в строке с «id»=1. Если не писать команду WHERE - поменяются все строки, а не конкретная.
Рекомендую вам приобрести книгу «SQL для чайников ». С ее помощью вы сможете шаг за шагом профессионально работать с БД. Вся информация построена по принципу от простого к сложному, и будет хорошо восприниматься.

Как удалить запись
Если вы написали что-то не так, исправьте это при помощи команды DELETE. Работает так же, как и UPDATE. Пишем такой код:
DELETE FROM ‘table’ WHERE id = ‘1’
Выборка информации
Для извлечения значений из БД используется команда SELECT. Пишем такой код:
SELECT * FROM ‘table’ WHERE id = ‘1’
В данном примере в таблице выбираем все имеющиеся поля. Это происходит если прописать в команде звездочку «*». Если нужно выбрать какое-то выборочное значение пишем так:
SELECT log , pass FROM table WHERE id = ‘1’
Необходимо отметить, что умения работать с базами данных будет недостаточно. Для создания профессионального интернет-проекта придется научиться добавлять на страницы данные из БД. Для этого ознакомьтесь с языком веб-программирования php. В этом вам поможет классный курс Михаила Русакова .

Удаление таблицы
Происходит при помощи запроса DROP. Для этого напишем такие строки:
DROP TABLE table;
Вывод записи из таблицы по определенному условию
Рассмотрим такой код:
SELECT id, countri, city FROM table WHERE people>150000000
Он отобразит записи стран где населения больше ста пятидесяти миллионов.
Объединение
Связать вместе несколько таблиц возможно используя Join. Как это работает посмотрите подробнее в этом видео:
PHP и MySQL
Еще раз хочу подчеркнуть, что запросы при создании интернет-проекта - это обычное дело. Чтобы их использовать в php-документах выполните такой алгоритм действий:
- Соединяемся с БД при помощи команды mysql_connect();
- Используя mysql_select_db() выбираем нужную БД;
- Обрабатываем запрос при помощи mysql_fetch_array();
- Закрываем соединение командой mysql_close().
Важно! Работать с БД не сложно. Главное - правильно написать запрос.
Начинающие вебмастера подумают. А что почитать по этой теме? Хотелось бы порекомендовать книгу Мартина Грабера «SQL для простых смертных ». Она написана так, что новичкам все будет понятно. Используйте ее в качестве настольной книги.

Но это теория. Как же обстоит дело на практике? В действительности интернет-проект нужно не только создать, но еще и вывести в ТОП Гугла и Яндекса. В этом вас поможет видеокурс «Создание и раскрутка сайта ».

Видео инструкция
Остались еще вопросы? Посмотрите подробнее онлайн видео.
Вывод
Итак, разобраться с написанием sql запросов не так трудно, как кажется, но сделать это нужно любому вебмастеру. В этом помогут видеокурсы, описанные выше. Подпишитесь на мою группу ВКонтакте чтобы первыми узнавать о появлении новой интересной информации.
Запросов - структурированных запросов к базе данных. Почему именно курс программирования ? Несмотря на то, что многие “буквоеды” будут утверждать, что SQL – это не , а язык запросов , я считаю, что курсы по его изучению можно и нужно относить к курсам программирования. Во-первых, не называть же их курсами составления запросов, поскольку так их могут перепутать с курсами для начинающих чиновников или прокуроров. Во-вторых, работа с базами данных настолько тесно переплетается с , что невладение навыками SQL довольно сильно сужает область применения того или иного программиста. Ну и в-третьих, структурированные запросы (не обязательно к базам данных) уже давно не на подступах к границам языков программирования – они ее уже перешагнули, и примером этому может служить технология .
Все примеры построены вокруг запросов к трем таблицам,
содержащим следующую информацию:
- D_STAFF
- список сотрудников компании;
- S_NAME – Ф.И.О.
- S_POSITION – должность (справочник);
- S_EXPERIENCE – стаж работы (целое количество лет);
- S_CHIEF_ID – вышестоящий сотрудник компании (отношение “начальник”-“подчиненный”);
- S_COMMENTS – примечание.
- D_PROFIE
– список профилей пользователей , которая, по легенде, развернута на территории рассматриваемого предприятия и помогает автоматизировать некоторые его бизнес-процессы. Этой системой могла бы быть как отечественная разработка “1С – Предприятие”, так и система на базе программного комплекса SAP R/3, являющегося наиболее ярким представителем такого класса программного обеспечения за рубежом;
- XD_IID – Уникальный идентификатор записи;
- P_NAME – наименование профиля (роли);
- P_COMMENTS – примечание.
- D_STAFF_PROFILE – таблица, связывающая сотрудников компании (D_STAFF) с профилями пользователей системы (D_PROFILE). Каждая запись в этой таблице - это связь, которая определяет возможность сотрудника входить в систему со всеми правами и разрешениями выбранного для него профиля. Каждый сотрудник может иметь несколько разрешенных ему профилей, а любой профиль может быть связан с несколькими различными сотрудниками. Таким образом, таблица D_STAFF_PROFILE определяет связь "многие-ко-многим".
Краткий обзор синтаксиса рассматриваемых SQL запросов
Обновление данных или команда UPDATE
Назначение команды UPDATE – обновление существующих записей в указанной таблице. Указываем, где и чего хотим изменить, а после ключевого слова WHERE устанавливаем критерии отбора обновляемых записей. В команде обновления данных, как и в других SQL запросах, можно использовать подзапросы: например, можно определить в качестве присваиваемого полю значения результат подзапроса, который возвращает только одну колонку и одну строчку.
UPDATE SET { = } или UPDATE SET { = (SELECT FROM WHERE)}
Добавление данных или команда INSERT
Добавление новых записей в указанную таблицу. Здесь тоже ничего сложного. Указываем таблицу, список полей и список добавляемых в эти поля значений. Что может дать использование SQL подзапроса тоже догадаться несложно - копирование выбранного с помощью SELECT массива данных в указанную таблицу (в перечисленные через запятую поля). Естественно, что количество и тип колонок в запросе SELECT должен соответствовать количеству и типу полей таблицы, куда производится вставка.
INSERT INTO [()] VALUES () или INSERT INTO [()] (SELECT FROM WHERE)
Удаление данных или команда DELETE
Удаление строк из одной таблицы или сразу из нескольких таблиц, строки которых объединены условиями. Здесь все также очевидно. Указываем, из какой таблицы удаляем данные, а в части WHERE отбираем удаляемые данные. Во втором варианте SQL запроса с использованием инструкции DELETE показан обобщенный синтаксис удаления записей сразу из нескольких таблиц. В условиях отбора (в части WHERE) также можно использовать подзапросы.
DELETE FROM или DELETE FROM
Если все более или менее понятно, то знакомимся с или и начинаем сам процесс обучения.
Выполнение простейших SQL запросов с использованием команды SELECT. Определение простых и составных критериев отбора записей посредством конструкции WHERE. Применение операторов BETWEEN и LIKE. Построение иерархического запроса с использованием псевдонимов таблиц и полей.
Представляю Вашему вниманию вольный перевод статьи SQL for Beginners
Все больше современных веб-приложений взаимодействуют с базами данных, обычно используя язык SQL . К счастью для нас, этот язык довольно прост в изучении. В этой статье мы начнем изучение основ SQL-запросов и их взаимодействие с базой данных MySQL .
Что вам нужно
SQL (структурированный язык запросов) - язык разработанный для взаимодействия с реляционными системами управления базами данных (СУБД), таких как MySQL, Oracle, Sqlite и другими. Для выполнения SQL-запросов из этой статьи, я полагаю, что у вас установлен MySQL . Так же рекомендую использовать phpMyAdmin как визуальное средство отображения для MySQL .
Следующие приложения позволят легко установить MySQL и phpMyAdmin на ваш компьютер:
- WAMP для Windows
- MAMP для Mac
Приступим к выполнению запросов в командной строке. WAMP уже содержит ее в консоли MySQL . Для MAMP , возможно потребуется прочитать вот это.
CREATE DATABASE: Создание базы данных
Наш самый первый запрос. Мы создадим базу данных, с которой будем работать.
Первым делом откройте консоль MySQL и залогинтесь. Для WAMP , по-умолчанию, используется пустой пароль. Для MAMP пароль должен быть "root".
После входа напечатайте вот этот запрос и нажмите Enter :
CREATE DATABASE my_first_db;
Обратите внимание, точка с запятой (;) добавляется в конце запроса, так же как в конце строки в коде.
Так же, ключевые слова CREATE DATABASE нечувствительны к регистру, как и все ключевые слова в SQL . Но мы будем писать их в верхнем регистре для улучшения читаемости.
На заметку: набор символов и порядок сопоставления
Если вы хотите установить набор символов и порядок сопоставления по-умолчанию, используйте подобный запрос:
CREATE DATABASE my_first_db DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
Вы найдете список поддерживаемых наборов символов и сопоставлений в MySQL .
SHOW DATABASES: Список всех баз данных
Этот запрос используется для отображения всех баз данных.

DROP DATABASE: Удалить базу данных
С помощью этого запроса вы можете удалить существующую базу данных.

Будьте осторожны с этим запросом, потому что он не выводит никаких предупреждений. Если у вас есть таблицы и данные в базе данных, запрос удалит их все в одно мгновение.
С технической точки зрения это не запрос. Это "оператор" и не требует точки с запятой в конце.

Он сообщает MySQL , что нужно выбрать базу данных по-умолчанию и работать с ней до конца сессии. Теперь мы готовы создать таблицы и остальное в этой базе данных.
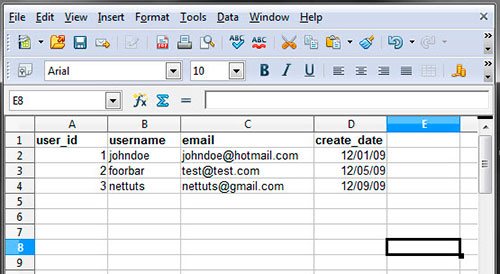
Что такое таблица базы данных?
Вы можете думать о таблице в базе данных как о обычной таблице или как о csv-файле, который имеет структурированные данные.

Как в этом примере, в таблице есть имена строк и столбцы с данными. Используя SQL-запросы мы можем создать эту таблицу. Еще мы можем добавлять, считывать, изменять и удалять данные.
CREATE TABLE: Создать таблицу
Этим запросом мы можем создать таблицу в базе данных. К сожалению документация по MySQL не очень дружелюбна к новым пользователям. Структура этого запроса может быть очень сложной, но мы начнем с простого.
Следующий запрос создает таблицу с двумя столбцами.
CREATE TABLE users (username VARCHAR(20), create_date DATE);
Обратите внимание, мы можем записать запрос на нескольких строках и использовать Tab для отступа.
С первой строкой все просто. Мы создаем таблицу с именем users . Далее, в скобках, перечисляются столбцы таблицы через запятую. После каждого имени столбца идет тип данных, например, VARCHAR или DATE .
VARCHAR(20) означает, что столбец строкового типа и может быть не более 20 символов в длину. DATE - тип данных предназначенный для хранения дат в формате: "YYYY-MM-DD".
Первичный ключ
Перед тем как выполним этот запрос, мы должны вставить столбец user_id , который будет первичным ключом (PRIMARY KEY). Не вдаваясь в подробности, вы можете думать о первичном ключе как о способе распознать каждую строку данных в таблице.
Запрос становится таким:
CREATE TABLE users (user_id INT AUTO_INCREMENT PRIMARY KEY, username VARCHAR(20), create_date DATE);
INT - 32х битный целочисленный тип (числовой). AUTO_INCREMENT автоматически создает новый номер id каждый раз при добавлении строки данных. Оно не обязательно, но с ним удобнее.
Этот столбец может быть не целочисленным, хотя это самый распространенный тип данных. Столбец с первичным ключом не обязателен, но рекомендуется его использовать для улучшения производительности и архитектуры базы данных.
Давайте выполним запрос:

SHOW TABLES: Список всех таблиц
Запрос позволяет получить список всех таблиц в текущей базе данных.

EXPLAIN: Показать структуру таблицы
Используйте этот запрос для того, чтобы посмотреть структуру существующей таблицы.

В результате показаны поля (столбцы) и их свойства.
DROP TABLE: Удалить таблицу
Как и DROP DATABASES , этот запрос удаляет таблицу и ее содержимое без каких либо предупреждений.

ALTER TABLE: Изменить таблицу
Такой запрос может иметь сложную структуру , потому что может совершать множественные изменения в таблице. Посмотрим на простые примеры.
Благодаря читабельности SQL , этот запрос не нуждается в объяснении.


Удалить так же просто. Используйте запрос с осторожностью, данные удаляются без предупроеждений.
Заново добавим поле email , позже оно еще понадобится:
ALTER TABLE users ADD email VARCHAR(100) AFTER username;
Иногда вам может понадобится изменить свойства столбца, для этого не обязательно его удалять и создавать опять.

Этот запрос переименовывает поле username в user_name и изменяет его тип с VARCHAR(20) на VARCHAR(30) . Такие изменения не влияют на данные в таблице.
INSERT: Добавляем данные в таблицу
Давайте добавим записи в таблицу, используя запросы.

Как вы можете видеть, VALUES() содержит список значений, разделенный запятыми. Строковые значения заключаются в одинарные кавычки. Значения должны следовать в порядке, заданном при создании таблицы.
Обратите внимание, первое значение равно NULL для первичного ключа, поле которого мы назвали user_id . Все потому что поле отмечено как AUTO_INCREMENT и id генерируется автоматически. Первая строка данных будет иметь id равный 1. Следующая добавленная строка - 2 и т.д.
Альтернативный синтаксис
Вот другой синтаксис вставки строк.

На этот раз мы использовали ключевое слово SET вместо VALUES . Отметим несколько вещей:
- Столбец может быть опущен. Например, мы не присвоили значение полю user_id , потому что оно отмечено как AUTO_INCREMENT . Если не присвоить значение полю с типом VARCHAR , то по-умолчанию оно примет значение пустой строки (если другое значение по-умолчанию не было задано при создании таблицы).
- К каждому столбцу можно обращаться по имени. Поэтому поля могут идти в любом порядке, в отличии от предыдущего синтаксиса.
Альтернативный синтаксис номер 2
Вот еще один пример.

Как и раньше к полям можно обращаться по имени, они могут идти в любом порядке.
Используйте этот запрос для того, чтобы получить id последней вставленной строки.

NOW()
Пришло время показать вам как использовать функции MySQL в запросах.
Функция NOW() возвращает текущую дату. Используйте ее для автоматического добавления текущей даты в поле с типом DATE .

Обратите внимание, что мы получили предупреждение от MySQL , но это не так важно. Причина в том, что функция NOW() фактически возвращает информацию о времени.

Мы создали поле create_date , которое может содержать только дату, но не время, поэтому данные были усечены. Вместо NOW() мы могли бы использовать CURDATE() , которая возвращает только текущую дату, но в конечном итоге результат был бы тем же.
SELECT: Получение данных из таблицы
Очевидно, что данные которые мы записали бесполезны пока мы не можем их прочитать. На помощь приходит запрос SELECT .
Простейший пример использования запроса SELECT для чтения данных из таблицы:

Звездочка (*) означает, что мы хотим получить все столбцы таблицы. Если вам надо получить только определенные столбцы, используйте что-то вроде этого:

Чаще всего мы хотим получить только определенные строки, а не все. Например, давайте получим E-mail адрес пользователя nettuts .

Он подобен условию IF. WHERE позволяет задать условие в запросе и получить нужный результат.
Для условия равенства используется одиночный знак (=), а не двойной (==), который, возможно, вы используете в программировании.
Так же вы можете использовать другие условия:

AND и OR используются для комбинирования условий:

Обратите внимание, числовые значения не нужно заключать в кавычки.
IN()
Применяется для сравнения с несколькими значениями.

LIKE
Позволяет задавать шаблон для поиска.

Знак процента (%) используется для задания шаблона.
Условие ORDER BY
Используйте это условие, если хотите чтобы результат возвращался отсортированным:

По-умолчанию задан порядок ASC (по возрастанию). Добавьте DESC для сортировки в обратном порядке.
LIMIT … OFFSET …
Можно ограничивать количество возвращаемых строк.

LIMIT 2 берет две первых строки. LIMIT 1 OFFSET 2 берет одну строку, после первых двух. LIMIT 2, 1 означает тоже самое, только первое число это смещение, а второе - ограничивает количество строк.
UPDATE: Обновление данных в таблице
Этот запрос используется для обновления данных в таблице.

В большенстве случаев используется вместе с WHERE , для того чтобы обновить определенные строки. Если условие WHERE не задано, то изменения будут применены ко всем строкам.
Для ограничения изменяемых строк, можно использовать LIMIT .

DELETE: Удаление данных из таблицы
Как и , этот запрос часто используется совместно с условием WHERE .

TRUNCATE TABLE
Для удаления содержимого из таблицы, используйте такой запрос:
DELETE FROM users;
Для повышения производительности используйте .

Также сбрасыват счетчик поля AUTO_INCREMENT , поэтому вновь добавленные строки будут иметь id равный 1. При использовании этого не произойдет и счетчик будет дальше рости.
Экранирование строковых значений и специальные слова
Строковые значения
Некоторые символы нужно экранировть, иначе могут быть проблемы.

Обратный слэщ (\) используется для экранирования.
Это очень важно по причинам безопасности. Любые пользовательские данные, перед записью в базу данных, должны быть экранированы. В PHP используйте функцию mysql_real_escape_string() или подготовленные запросы.
Специальные слова
Поскольку в MySQL много зарезервированных слов, таких как SELECT или , во избежании противоречий, заключайте имена столбцов и таблиц в кавычки. Причем нужно использовать не обычные кавычки, а обратные (`).
Допустим, по каким то причинам, вы хотите добавить столбец с именем :

Заключение
Спасибо за прочтение статьи. Надеюсь я сумел показать вам, что язык SQL очень функционален и легок в изучении.